Venice is a privacy-focused AI platform. It has three main differentiators:
-
Private: It doesn’t store your conversations or use them for model training. Processing is done through decentralized GPU networks, not central servers
-
Uncensored: Unlike mainstream AI, it has no built-in content filters. You control the AI’s behavior through “system prompts”
-
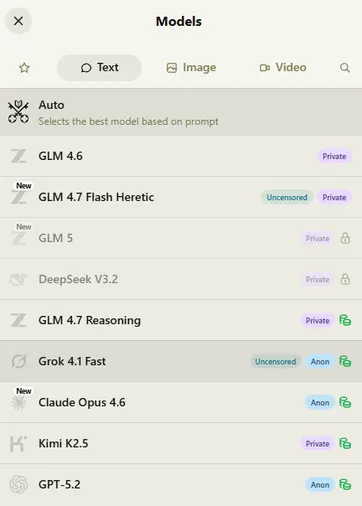
Multi-Modal: Venice lets users shift between Claude, GPT, Gemini, as well as top open-source models (DeepSeek and Llama) through a single interface.
Venice employs a familiar business model: a free tier with basic models and conservative usage limits, along with an $18/month pro tier. Users can pay with fiat, USDC, or earn membership by staking 100 VVV tokens. Venice has over 2M users and 55K paying subscribers.
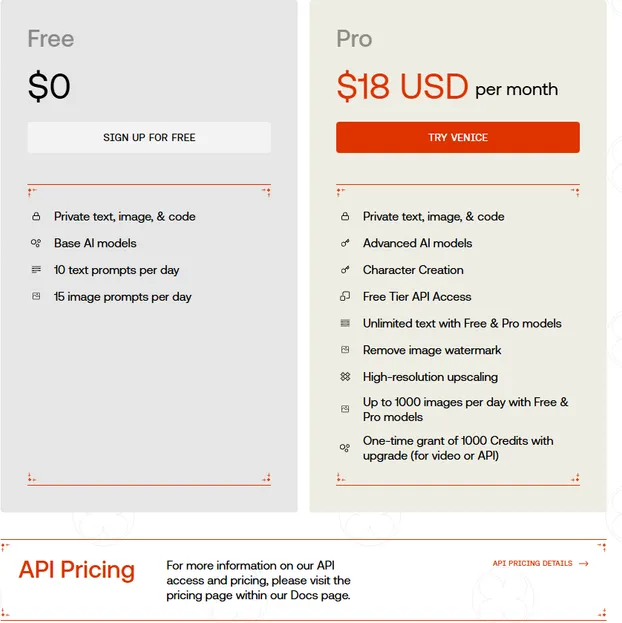
Venice is essentially a private Cursor, but geared toward general use over coding. The value proposition for users is clear: users get access to numerous models with better privacy for the same price as individual pro memberships.
Architecture
Venice offers different levels of privacy based on the model type.
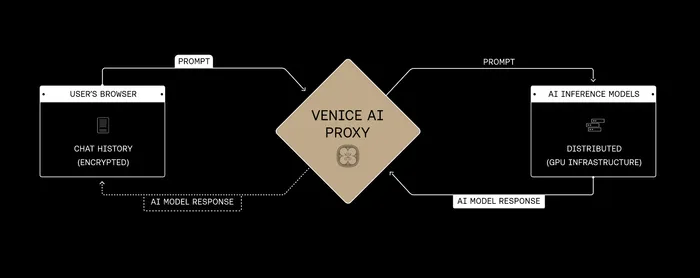
Open source models: Venice manages a fleet of GPUs that they operate in data centers to run the open source models with zero data retention (ZDR) guarantees. User prompts are encrypted in the browser, sent to the proxy server, and routed to the GPU for processing. These are labelled “Private” in the model list.
There are no “random untrusted computers” on Venice
We manage a fleet of GPUs that we control in datacenters with ZDR guarantees. These are labelled “Private” in the model list.
For exogenous models from the closed-source providers, like Claude/Gemini, they are labelled…
— Erik Voorhees (@ErikVoorhees) March 2, 2026
Conversations are stored locally on the user’s device, not on company servers. No data monitoring or collection. The GPUs only have access to the current conversation.
Proprietary models: Venice cannot run the closed-source models such as Claude, Gemini on decentralized GPUs. The model providers will still see (and likely log) all information from prompts received by Venice. Venice here acts as a mixer, preventing Anthropic or OpenAI from linking the prompt from any specific Venice user. These models are labeled “Anonymous.”
Token
VVV is the capital asset token of Venice. VVV can be staked to earn Pro access and earn yield from VVV emissions. Staked VVV grants users pro rata access to Venice’s total API capacity.
Initially, this access feature was seamlessly rolled into the VVV token. The amount of free inference received daily share of compute was variable and unpredictable, due to fluctuating capacity and staking ratios. This made budgeting difficult for stakers and developers.
Therefore, the compute access was tokenized into DIEM. DIEM can only be minted by VVV lockers, and represents a fixed, perpetual, and transferable right to AI compute. 1 DIEM represents $1 of API credit per day in perpetuity.
Each month, Venice uses a portion of revenue in discretionary buybacks of VVV.
Catalyst
VVV is on a tear, up 4x in 3 weeks. This rally has been accelerated by news that it is the preferred model provider for Openclaw.
Venice mindshare has skyrocketed along with the pump, bringing scrutiny over its privacy model and causing the Openclaw creator to retract the preferred provider endorsement, calling it an oversight.
Yeah this was an older doc oversight, we wanna be neutral on this.
— Peter Steinberger 🦞 (@steipete) March 2, 2026
The privacy concerns are not unfounded, there are indeed trust assumptions in the model. Venice has shifted from using decentralized GPU networks such as Akash to running their own GPUs. In either instance, the GPUs can see the prompts. The proxy server is another major trust assumption, and the source of the “trust me bro” critique floating around. The lack of transparency in revenue and user metrics doesn’t help, and the docs are outdated in many areas.
Venice is not really private. ( $VVV )
To be clear, Venice itself doesn’t log user data, and there isn’t a centralized company harvesting prompts.
But inference is handled by GPU DePIN networks like Akash and Hyperbolic, where individuals like you and me, or data centers,… pic.twitter.com/wm7doL9kbA
— milian (@milianstx) March 3, 2026
That being said, a mixer for the top models is still a massive improvement. Erik Vorhees has stated that there will be further privacy improvements. Improving transparency around platform metrics and mitigating trust assumptions where possible could fortify Venice as the leader in a very attractive new narrative.
TLDR
-
Real product, incredibly hot narrative, first mover, interesting and unique tokenomics.
-
Obscure metrics, privacy model scrutiny, unclear valuation framework (is Cursor’s $28B val the best comp?)
The Openclaw endorsement retraction and privacy FUD could provide a nice entry. More detailed analysis coming soon.