AI development’s edge no longer hinges on how many GPU-hours a team can burn, but on the profit each hour returns. Models like GPT-4.1 exemplify this, delivering million-token reasoning capabilities while significantly lowering inference costs. As shrinking safety budgets, accelerated model-release cycles, and the evolution toward dynamic benchmarks (rather than static accuracy tests) reshape the industry’s priorities, the initiative to maximize Return-on-GPU (RoG) has come sharply into focus.
This pivot toward efficiency, specialization, and composability is exactly the direction guiding my own research priorities:
Yet this transition to RoG-based frameworks reveals two fundamental vulnerabilities within the centralized cloud computing model. The first is blind trust: current cloud platforms do not provide hard evidence verifying that inference outputs are correct and have not been tampered with. The second is brittle scaling: the sophisticated but centralized GPU clusters that hyperscalers rely on lose efficiency once workloads extend across diverse geographies, heterogeneous hardware setups, or regulatory boundaries.
Decentralized AI (DeAI) networks, which leverage verifiable compute and semi-synchronous (or fully asynchronous) distributed training methods, are uniquely positioned to address these twin issues. By permissionlessly enabling computational tasks across distributed, heterogeneous GPU clusters (and ensuring their correctness through cryptographic validation) these networks hold the promise of simultaneously improving per-unit efficiency, and transparency. If decentralized platforms can demonstrate that they are compliant with regulations and offer robust integrity guarantees, they will eventually stand to challenge hyperscalers directly on the fronts of economics, reliability, and operational sovereignty. Early adopters like Prime Intellect and Inference Labs have already started working to deliver provably correct inference across geographically dispersed GPUs. No longer just being experimental curiosities, these DeAI initiatives are validating verifiable compute and permissionless distributed training and setting a clear direction for industry-wide transformation.
This report traces the shift toward RoG optimization, surfaces issues of trust and scale fault, and evaluates whether DeAI mechanisms form a viable path to credibly and sustainably rival centralized cloud incumbents.
In short: The shift towards RoG will, in time, reward those who deliver provable trust and reliable scale, rather than only rewarding those who own the largest clusters.
RoG in Practice
OpenAI announced that they will sunset GPT-4.5 and fully transition to GPT-4.1. Rising costs combined with sluggish response times have exposed raw computational scaling’s inherent limitations as a long-term strategy. In practice, GPT-4.1 achieves roughly 26% lower inference costs compared to GPT-4o, and introduces a one-million-token context window without additional fees.
GPT-4.1 increases the return per GPU by sharpening two existing mechanisms:
- Diff-editing reliability – 4.1 now only suggests the essential code changes, cutting unnecessary exits by ~ 78%
- Prompt-caching efficiency – the model more efficiently reuses computations when the initial 1,024 tokens of a prompt repeat, increasing inference cost savings on those reused tokens from 50% to ~ 75%
The following table details GPT-4.1’s key technical optimizations and their impacts:
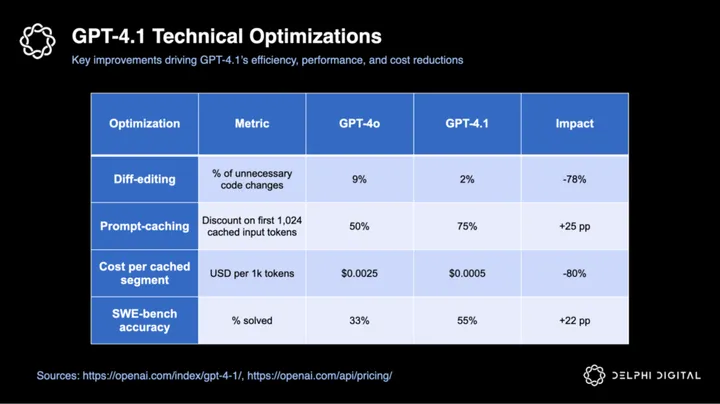
Greater RoG directly translates into measurable productivity gains. For instance, GPT-4.1’s optimizations drove a notable 22-point accuracy improvement on SWE-bench (from 33% to 55%), significantly cutting real-world engineering hours.
With GPT-4.5 scheduled for retirement on July 14th, the freed GPU resources are being reallocated toward training and deploying GPT-5. This move signals OpenAI’s prioritization of future readiness while also emphasizing their broader shift toward maximizing returns on compute investments.
I believe investors will increasingly view Return-on-GPU (RoG) as an essential metric for evaluating model value, selecting infrastructure partners, and understanding underlying model economics. These RoG gains raise the bar for hyperscalers and, in time, create headroom for permissionless, verifiable, and distributed AI networks to compete on both cost and trust.
Benchmarking Is Breaking
Classic benchmark leaderboards miss crucial dimensions of model performance because they rely heavily on isolated, single-turn accuracy metrics rather than tests that closely mimic real-world workflows. By surfacing subtle hallucinations, context drift, and biased reasoning that single-shot accuracy tests (e.g. AIME ’24, GPQA Diamond) don’t catch, interactive evaluations transform sustained, process-oriented performance into a direct proxy for trustworthiness. Ultimately, trustworthiness hinges on humans’ ability to reliably ver
Unlock Access
Gain complete access to in-depth analysis and actionable insights.
Tap into the industry’s most comprehensive research reports and media content on digital assets.
Be the first to discover exclusive opportunities & alpha
Understand the narratives driving the market
Build conviction with actionable, in-depth research reports
Engage with a community of leading investors & analysts
0 Comments