Report Summary
Monolithic chains are bounded by what a single node can process, whereas modular ecosystems surpass this limitation, offering a more sustainable form of scaling.
A key motivation behind modularity is efficient resource pricing. Modular chains can offer more predictable fees by separating applications into different resource pools (i.e. fee markets).
Modularity, however, introduces a new problem known as data availability, which can be addressed several ways. Rollups, for example, batch off-chain data and submit it on-chain. By making the “data available” on-chain, they overcome this issue and inherit the underlying security of the base layer, establishing trustless L1<>L2 communication.
The newest form of modular chains, known as specialized data availability (DA) layers, is designed to act solely as a shared security layer for rollups. Given their scalability advantages, DA chains may become the end game of blockchain scaling. Celestia is the pioneering project on this front.
ZK-Rollups can offer more scalability than Optimistic Rollups, which is already being seen in practice. dYdX, for example, has been processing roughly 10x more throughput than Optimism while consuming 1/5th of it’s L1 footprint.
Introduction
On-chain activity is taking off at warp speed, and with it so is demand for blockspace. While Ethereum’s blocks have been nearly full for over a year, we’ve seen multiple L1 & L2 networks gain meaningful traction.
At its core, this is a scalability war. And this introduces technical terms like parachains, sidechains, bridges, zones, shards, rollups, data availability, and a plethora of others. In this post, we aim to dampen this noise and elaborate on this scalability war. So grab a cup of coffee or tea before you strap yourself in, because this is going to be a long ride.
Searching For Scalability
Ever since Vitalik’s famous scalability trilemma, there has been a misconception in the crypto community that the trilemma is set in stone and that everything must be a trade-off. While this is true most of the time, every now and then we see the boundaries of the trilemma stretched — either via real innovation or by introducing additional (but reasonable) trust assumptions.
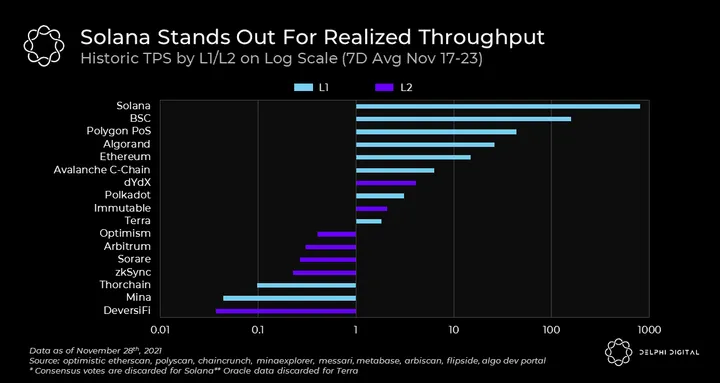
We highlight some of these examples as we go through the different designs. But before we start, it’s important to define what we mean by scalability. Put simply, scalability is the ability to process more transactions without increasing the cost to validate them. With that in mind, let’s take a look at current TPS figures for various chains. Throughout this post, we’ll explain the design properties that enable these varying levels of throughput. Importantly, the numbers shown below are not the max levels that can be achieved, but rather the actual historical levels which are dependent on usage.
Monolithic vs Modular

Monolithic Blockchains
First, let’s zoom in on standalone chains. Under this camp, Polygon PoS and BSC don’t match our scalability definition as they increase throughput via bigger blocks — a well-known trade-off that increases the resource requirement of nodes and sacrifices decentralization for a performance improvement. While this trade-off has its market fit, it’s less compelling as a long-term solution. Polygon, however, recognizes this and is pivoting to a more sustainable solution centered around rollups.
Solana, on the other hand, comes as a serious attempt to push the boundaries of a fully composable, monolithic chain. The secret sauce of Solana is known as the Proof of History (PoH) ledger. The idea with PoH is to create a global notion of time — a global clock — whereby all transactions, including consensus votes, carry reliable timestamps attached by the issuer. These timestamps allow nodes to make progress without waiting to synchronize with each other on every block. Solana further complements this ability by optimizing its execution environment to process transactions in parallel, as opposed to one at a time as in the case of EVM, to achieve a higher scale.
Even though Solana’s throughput gains are beyond what can be achieved by simple parameter tweaks, it’s still in large part owed to more intensive hardware and network bandwidth usage. While this lowers fees for users, it restricts node operations to data centers. This comes in contrast to Ethereum which, although inaccessible to many due to exorbitant fees, is ultimately governed by its active users who can run nodes from home.
Where Monolithic Chains Fail
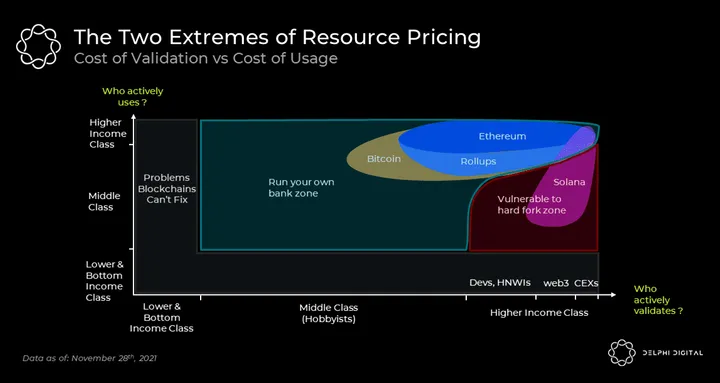
Scalability in a monolithic chain is ultimately bounded by what a single, powerful node can process. Regardless of subjective opinions on decentralization, this capacity can only be pushed so hard before it restricts governance into the hands of relatively few actors. In contrast, modular chains split the total work among different nodes so that more throughput can be produced in total than what any single node can process.
Crucially, decentralization is only one-half of the modularity picture. The other motivation behind modular chains, as important as decentralization, is efficient resource pricing (i.e. fees). In a monolithic chain, all transactions compete for the same blockspace and consume the same resources. Naturally, in the scenario where a chain gets crowded, outsized demand for a single app has adverse effects for all apps on the chain as fees rise for everyone. This has been Ethereum’s reality ever since CryptoKitties clogged the network in 2017. Importantly, additional throughput never really solves the problem once and for all – it merely postpones it. The internet’s history tells us that every additional capacity increment makes room for new, otherwise infeasible applications which tend to quickly consume the additional capacity that has just been added.
Finally, a monolithic chain simply can’t optimize itself for vastly different applications with different priorities. In the case of Solana, one example could be Kin and Serum DEX. Solana’s low latency is suitable for an app like Serum DEX. However, maintaining such latency also necessitates a restriction on state growth which is enforced by charging a state rent for every account. This, in turn, has adverse effects on account-heavy applications like Kin who can’t offer Solana’s throughput to the masses due to high fees.
Looking into the future, it’s naïve to expect a single resource pool to reliably support the diverse range of applications crypto enables; from the Metaverse and gaming to DeFi and payments. While increasing the throughput capacity of a fully composable chain is useful, we need a wider design space and better resource pricing for mainstream adoption. This is where modular approaches come into play.
The Evolution of Blockchains
In the holy mission of scaling, we’re witnessing a trend shift from “composability” to “modularity”. First, to define these terms: composability refers to the ability for applications to seamlessly interact with one another in friction minimized fashion while modularity is the facility for a system to be broken down into multiple individual parts (modules) that can be stripped and re-assembled at will.
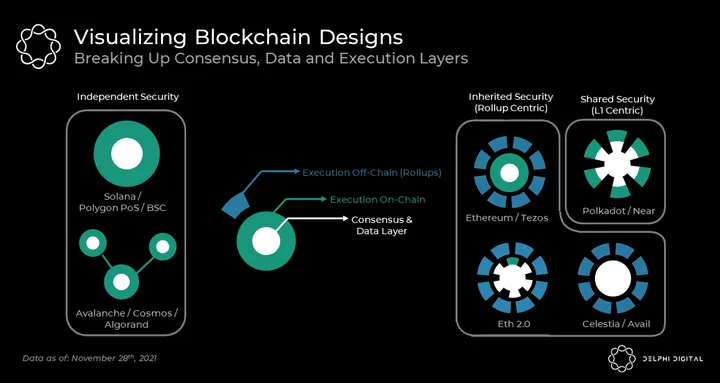
Ethereum Rollups, ETH 2.0 Shards, Cosmos Zones, Polkadot Parachains, Avalanche Subnets, Near’s Chunks, and Algorand Co-Chains can all be thought of as modules. Each of these modules processes a subset of the total workload in their respective ecosystems while maintaining the ability to cross-communicate. As we dive deeper into these ecosystems we will notice that modular designs greatly vary with how they approach security across modules. Multi-chain hubs like Avalanche, Cosmos, and Algorand are most suited for independently secured modules whereas Ethereum, Polkadot, Near, and Celestia (a relatively new L1 design) envision modules that ultimately share or inherit security from one another.
Multi-Chain / Multi-Network Hubs
The simplest modular design is known as interoperability hubs. This refers to multiple chains/networks which communicate with each other through a standard protocol. Hubs enable a wider design space as they can have application-specific chains customized on many different levels; this includes the virtual machine (VM), node requirements, fee models, and governance. An app-chain’s flexibility can’t be matched by smart contracts on a general-purpose chain. Let’s briefly go over some examples:
- Terra, which powers more than $8B worth of decentralized stablecoins, has a special fee and inflation model optimized for the adoption and stability of its stablecoins.
- Cross-chain DEX Osmosis, which currently processes the largest IBC throughput, wants to encrypt its transactions until they are finalized to prevent front-running.
- Algorand and Avalanche aim to host enterprise use cases on custom networks. These can range anything from a CBDC run by government agencies to a gaming network run by a committee of gaming companies. Importantly, the throughput of such networks can be boosted by beefier machines without impacting the decentralization level of other networks/chains.
Hubs also offer scalability advantages to the extent that they provide more efficient use of resources. Take Avalanche as an example. The C-Chain is for EVM compatible smart contracts while the X-Chain is for P2P payments. Because payments can often be independent of each other (Bob paying Charlie is not dependent on Alice paying Dana), the X-Chain can concurrently process certain transactions. By separating the VMs based on their core utility, Avalanche can thus process more transactions.
These ecosystems can also vertically scale through fundamental innovations. Avalanche and Algorand particularly stand out here as they achieve a higher scale by reducing the communication overhead of consensus. Avalanche does this through a “sub-sampled voting” process while Algorand uses a cheap VRF for nodes to randomly select a unique committee for consensus on every block.
So far, we’ve laid out the advantages of the hubs. However, this approach hits some key limitations as well. The most obvious limitation is the need for chains to bootstrap their own security, as they are unable to share or inherit security from one another. It’s known by now that any secure cross-chain communication requires a trusted third party or synchrony assumption. In the case of hubs, the trusted third party becomes the majority validators of the counterparty chain.
For example, a token pegged from one chain to another via IBC can always be redeemed out (stolen) by a malicious majority of source-chain validators. This majority trust assumption may work fine today where only a handful of chains co-exist. However, in an possible future where there are a long tail of chains/networks, expecting these chains/networks to trust each other’s validators to communicate or share liquidity is far from ideal. This brings us to rollups and sharding that offer cross-communication with stronger guarantees beyond majority trust assumptions.
(While Cosmos will introduce shared staking across Zones and Avalanche can have multiple chains validated by the same network, these solutions are less scalable as they impose heavier requirements on validators. In practice they are likely to be adopted by most active chains and not the long tail.)
Data Availability
After years of blood sweat and tears, it has become widely accepted that all security sharing efforts boil down to a very subtle problem called data availability. To understand why, we must shortly re-visit how nodes operate in a typical blockchain.
In a typical blockchain, full nodes download and validate all transactions while light nodes — who don’t have the necessary resources for intensive audits (99% of users) — only check block headers (summary of the block committed by majority validators). As such while full nodes can independently detect and reject invalid transactions (for ex. unlimited printed tokens), light nodes deem whatever the majority commits to as a valid transaction.
To improve on this, ideally, any single full node can protect all light nodes by issuing small-sized proofs. Under such design, light nodes can operate with similar security guarantees as full nodes without spending as many resources. However, this introduces a new problem known as DA.
If malicious validators publish a header, yet withhold some or all transactions in the block, full nodes won’t be able to tell if the block is valid because the missing transaction(s) may be invalid or cause a double spend. Without this knowledge, full nodes can’t generate a fraud-proof for invalidity to protect light nodes. In conclusion, for a protection mechanism to work in the first place, light nodes must make sure that a full and complete list of all transactions has been made available by validators.
The DA problem is an indispensable part of modular designs looking to go beyond majority trust assumptions when it comes to cross-communication. What makes rollups special amongst L2s is that they don’t try to get around this problem.
Rollups
In the context of rollups, we can think of the main chain (Ethereum) as a light node to the rollup (Arbitrum). Rollups post all their transaction data on L1 so that any L1 node willing to put the resources together can execute them and construct the rollup state from scratch. With the full state at hand, anyone can transition the rollup into a new state and prove the validity of the transition by issuing validity or fraud-proof. Having data available on the main chain allows rollups to operate under a negligible single honest node assumption instead of an honest majority.
Consider the following to understand how rollups achieve better scalability with this design:
- Since any single node with the current rollup state can protect all others without the state, centralization of rollup nodes is less of a risk, and therefore rollup blocks can be made reasonably bigger.
- Even though all L1 nodes download a rollup’s data with regards to their transactions, only a fraction of them execute these transactions and construct the rollup state, thereby reducing overall resource consumption.
- A rollup’s data is compressed using clever techniques before getting posted on L1.
- Similar to app chains, rollups can tailor their VM for specific use cases which implies more efficient use of resources.
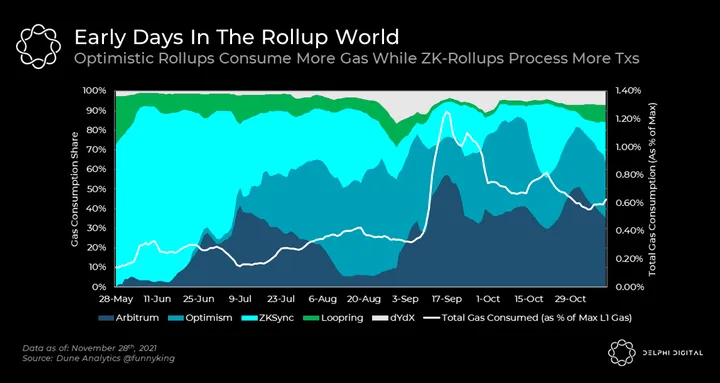
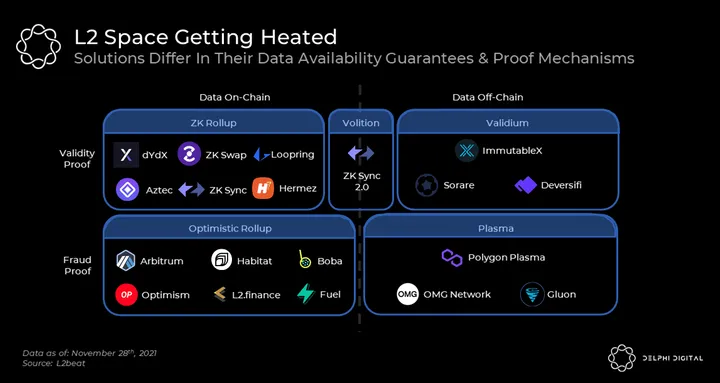
By now it’s common knowledge that there are two broad rollup categories: Optimistic rollups and ZK-rollups. From a scalability perspective, ZK-rollups are more advantageous than Optimistic rollups because they compress data in a more efficient manner thereby achieving a significantly lower L1 footprint for certain use cases. This nuance is already seen in practice. While Optimism posts data to L1 to reflect every transaction, dYdX posts it to reflect every account balance. As such, dYdX’s L1 footprint is 1/5th that of Optimism, and it’s estimated to process roughly 10x more throughput. This advantage naturally translates into lower fees for ZK-rollups.
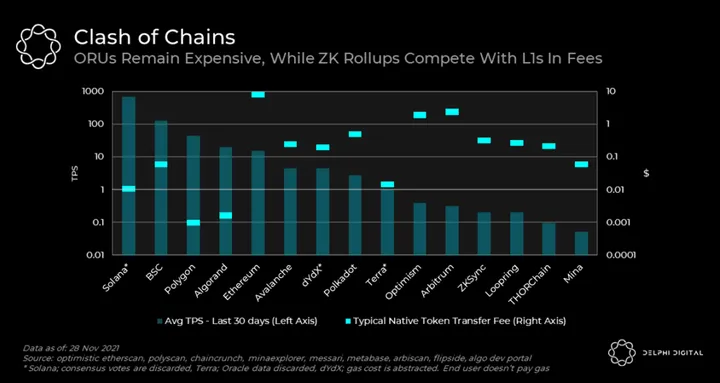
Unlike fraud-proofs on Optimistic rollups, validity proofs from a ZK-rollup also enable a new scalability solution known as volition. Although the full effects of volition remain to be seen, they seem very promising as it gives users the freedom to decide whether to post data on-chain or off-chain. This allows users to decide on their security level on a per transaction basis. Both zkSync and Starkware have volition implementations launching in the next weeks/months.
Even though rollups apply clever techniques to compress the data, all data must still be posted to all L1 nodes. Therefore rollups can only offer linear scalability gains and are limited in how much they can reduce fees. They’re also highly impacted by the volatility of Ethereum gas price. For sustainable scaling, Ethereum needs to scale its data capacity – which explains the need for Ethereum sharding.
Sharding & DA Proofs
Sharding further relaxes the requirement for all main chain nodes to download all data, but instead make use of a new primitive known as DA proofs to achieve higher scalability. With DA proofs, instead of all nodes downloading all of the data from every shard, each node downloads only a tiny fraction of shard chain data, knowing a minority of them can collectively reconstruct all shard chain blocks. This enables shared security across shards as it ensures that any single shard chain node can raise disputes to be resolved by all nodes on-demand. Polkadot and Near have already implemented DA proofs in their sharding design, and this will also be adopted by ETH 2.0.
At this point, it’s worth mentioning how ETH 2.0’s sharding roadmap differs from others. Although the initial roadmap of Ethereum was to shard execution just like Polkadot, it seems to have recently pivoted to sharding data only. In other words, shards on Ethereum will serve as DA layers for rollups, which in turn perform all the execution. This means Ethereum will continue to have a single state just like today. In contrast, Polkadot performs all execution on the base layer where each shard has a different state.
A major advantage of having shards as pure data layers is the flexibility for rollups to dump data on multiple shards while remaining fully composable. A rollup can therefore have throughput and fees unbounded by the data capacity of a single shard. With 64 shards, the max aggregate throughput of rollups is expected to increase from 5K TPS to 100K TPS. In contrast, no matter how much throughput Polkadot generates as a whole, fees will be bound by the limited throughput capacity of a single parachain (1000-1500 TPS).
Specialized DA Layers
Specialized DA layers are the latest form of modular blockchain design. They use the base idea of ETH 2.0’s DA layer, but steer it in a different direction. The pioneering project on this front is Celestia, but newer solutions such as Polygon Avail are also heading in this direction.
Similar to the DA shards of ETH 2.0, Celestia acts as a base layer that other chains (rollups) can plug into in order to inherit security. Celestia’s solution differs from Ethereum in two fundamental ways:
- It doesn’t perform any meaningful state execution at the base layer (and ETH 2.0 does). This frees rollups from highly unreliable base layer fees which, in a stateful environment, may spike any time there is a token sale, NFT airdrop, or high-yield farming opportunity. Rollups consume the same resources (i.e. bytes in the base layer) for security, and security only. This efficiency allows rollup fees to be predominantly tied to the usage of that particular rollup instead of the base layer.
- Celestia can grow its DA throughput without sharding thanks to DA proofs. A key property of DA proofs is that as more nodes participate in sampling, more data can be stored as there is additional collective work being done. In the context of Celestia, this means blocks can be made bigger (higher throughput) as more light nodes participate in DA sampling (without centralization).
As with all designs, specialized DA layers also carry some drawbacks. One immediate drawback is the lack of a default settlement layer. As such in order to share assets with each other, rollups will have to implement methods to interpret each other’s fraud proofs.
Conclusion
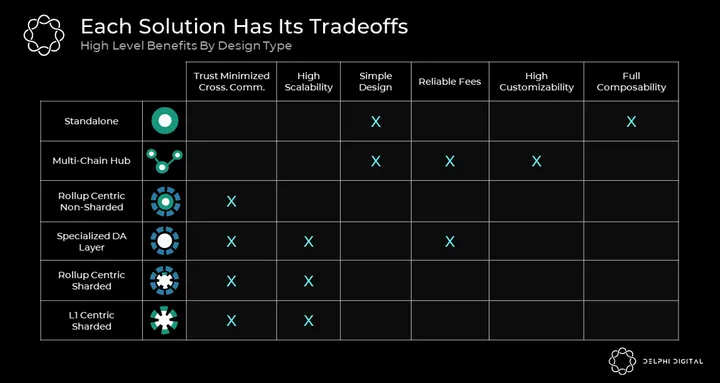
We have evaluated different blockchain designs including monolithic chains, multi-chain hubs, rollups, sharded chains, and specialized DA layers. Given their relatively simple infrastructure, wider design space and ability to expand horizontally we think multi-chain hubs are best suited to address the immediate needs of blockchain space. In the longer term, given their resource efficiency and unique scalability properties, specialized DA layers may very well be the end-game.
0 Comments