An Intro To The Current Gaming Landscape
The games industry continues to represent one of the largest and most accessible forms of global entertainment, with an estimated 3.3B gamers worldwide and $184B in revenue across mobile (49%), console (30%), and PC (21%) in 2023. Forecasts project a 2.5% CAGR in revenues from 2022 to 2026 and a 3% growth in the total number of players.
Industry trends continue to point to a future where more people spend more time playing games. Supporting this is the fact that younger generations are increasingly pro-gaming. 90% of Gen Z are considered “game enthusiasts,” with 17% spending their free time playing games. Encouragingly, these figures increase to 94% and 21%, respectively, for the relatively younger Gen Alpha. A closer look reveals what types of games are capturing the majority of this upside. Free-to-play (F2P) multiplayer live services (also referred to as Games-as-a-Service) have been and are expected to continue to drive the majority of industry growth.
A recent report by Unity showed that over 60% of developers are already making multiplayer games, and, on average, mobile-only games (the largest market segment) that contain multiplayer features had >40% more monthly active users (MAU). Multiplayer game revenues also grew by 10% ($2.3B) year-on-year in 2023 and are expected to increase by a further 7% by the end of 2024. A part of the reason why multiplayer games attract more users and make more money is because they can thrive in theoretical perpetuity. More concurrent players generate quadratically more social interactions and in-game transactions, which is a driving force behind many F2P game economies.
This is the age of live service F2P “forever games.” The top ten games by average MAU in 2023 were all over seven years old (excluding on the Switch). Titles such as GTA 5, Minecraft, Roblox, Counter-Strike, and Fortnite are supplying players with near-endless hours of amusement both inside and outside of the virtual world.
Leveraging a live service model has allowed some of these forever games to sustain players’ attention for a decade plus. The proliferation of mobile gaming has only served to increase distribution to consumers who would not typically have access to or be classified as gamers, and overall playtime has increased as we can now play games on the go. 
However, in recent years, industry growth projections have had to be readjusted due to a slower than expected market recovery following the post-covid slump. Moreover, these stifled growth metrics saw 2023 as the year of the most gaming-related layoffs ever – a figure that was surpassed in the first half of 2024.
Additionally, a recent survey shows that, in order to keep up with industry trends and consumer demands, 77% of developers report that the cost of game development is rising. Gamer’s attention is finite, and with 66% of developers believing that live service is necessary for long-term success and 95% stating they are either working on or intend to release a live service game, competition will continue to rise in what can sometimes look like a winner-takes-all arena.
We, therefore, find ourselves at an interesting intersection where the market for gamers is expanding at the same time that business growth is stagnating and execution risk is increasing. As content continues to trend toward live service forever games, industry leaders and would-be disruptors will need to innovate on business models, cost reduction, and distribution, and explore ways to deliver novel, fun experiences that last.
In order to have a chance to compete with the industry giants, many developers are evaluating new technological integrations to help them deliver robust net-new experiences. Looking past solutions such as AI and cloud computing, this report will take a deep dive into scaling virtual worlds and what implications it has for this industry’s future.
The Road To Scale
As the scope of persistent multiplayer experiences expands, so too will the need for content. There has already been a notable improvement in procedural generation (procgen) and text-to-image AI tools, along with the continued iterative steps forward made to leading game engine technology.
This has made scaling massive virtual worlds easier than ever before and democratized the ability for smaller teams to compete in the big leagues. However, more often than not, players are left feeling disappointed as AAA titles with 9-figure development budgets produce barren, empty lands that feel void of compelling content or dense multiplayer interactions.
In order to maintain a consistent content treadmill that appeals to a customer base within a highly competitive market, a growing number of projects are turning to user-generated content (UGC). Pushing content creation over to the community with the help of low/no-code UGC tools, aligned incentives, and cryptographically efficient value distribution will play an increasingly important role in the live service of a growing number of multiplayer games like Fortnite/UEFN, ARK: Survival Ascended, Shrapnel, and Maplestory Universe.
Not only will this help significantly scale the amount of content on offer, but it will also lighten the load and costs of operating a live service model. This will allow developers to focus on the core game design, large-level content updates, and bug fixes.
Additionally, advancements in LLMs and autonomous agents will drive innovation in immersive AI NPCs (non-player characters) and competitive bots. The days of vast, empty worlds will be long gone. Soon, they will be populated with thousands and eventually millions of players and AI agents, all adhering to complex and intractable simulation physics.
Rapid innovations in GPU hardware, cloud computing, pixel streaming, and graphical rendering solutions (Like Nvidia GeForce Now, Nvidia DLSS, Aethir, YOM, and Shaga) are already improving the performance, experience, and accessibility of hardware-intensive games across a wider range of devices. Further scaling the total addressable market across low-end mobile devices while also making games look and feel more immersive – a crucial component of any virtual simulation.
However, unlike graphical processing, which has seen a 10x increase in efficiency and output over the past decade (and will likely continue accelerating thanks to advancements in AI), CPU performance has been static for nearly 20 years. Built upon decades of bloated distributed compute systems, today’s backend computational architectures are inefficient.
In order to scale large content-rich virtual worlds for millions of concurrent players, intractable objects, and AI, the industry is in need of new solutions to old problems.
Hyperscale
Scale vs. Concurrency
It is important to add some more color on exactly what we mean by scale.
Scale, in the context of total players within any given game or platform, has seen consistent growth over the last couple of decades. For example, Steam maintains an average daily peak of ~32M users online at the same time, a figure that has grown over 350% over the past ten years.
The content side paints a similar picture. The top game by the number of players on Steam (and one of the world’s leading forever games) is Counter-Strike. Counter-Strike was launched in 2012 and today has almost 1.5M players online at any given moment, an increase of ~1,400% compared to 10 years prior.
Virtual concerts like the Travis Scott Fortnite performance attract millions of views (>27M unique players and over 46M views) but host fewer players in the same instance than a typical 32 vs. 32 round of Battlefield. Although there were a reported 12.3M concurrent spectators at this event, in reality, these users were split between multiple servers. The actual number of concurrent users (CCUs) per instance was closer to 50, severely limiting the scale of artist-to-fan interactions.
It’s notable that despite the headlines, this was actually lower than previous performances by Marshmello and Star Wars, which were estimated at roughly 100 CCUs. The fundamental compute infrastructure constraints, when combined with an increase in the number of interactable objects and physics complexity, as seen in the Travis concert, quickly decrease the number of CCUs if a certain level of fidelity and density is to be maintained.
Aside from the total number of players, there is also scale in terms of world size. This measure of scale is more a product of some of the technical advancements previously mentioned, such as procgen. Specifically, this is what helped the team at Hello Games create No Man’s Sky, a sci-fi world that could be populated with as many as 18 quintillion different variations of planets.
However, as previously mentioned, this approach to scale often results in empty, barren environments that have a direct negative impact on the player experience. Ultimately, this approach requires a time- and cost-intensive post-launch live service pipeline to produce content continuously in order to keep players engaged.
In this report, we will refer to scale as how many concurrent players (CCUs) can co-exist at the same time within a single shared world (otherwise referred to as a shard, as defined by one of the earliest innovators in scaled virtual experiences, Ultima Online). Importantly, scale, in this sense, should not take precedence over the player experience.
Therefore, scaled concurrency must exist in tandem with the 10 facets of scale: graphical fidelity, entity density, physics complexity, world size, player agency, real-time compute, consistency, latency, persistence, and cost (see Extras at the end of the report for more). Critically, scale must certainly not come at the cost of requiring an uneconomically outsized investment in developer time and resources. Only then can games reach hyperscale.
The challenge with concurrent scale is that it is generally complex and costly to maintain. It doesn’t take very long for games being built natively with Unity or Unreal Engine (UE) to hit very hard limits of scale. The typical maximum number of players in a single shard is capped at between 40 and 100 CCUs for Unity and between 80 and 200 for UE.
Note that we have left a detailed list of the 10 facets of hyperscale at the end of this report, and from this point on, we will simply refer to the above measure of scale as “hyperscale.”
A History of Scale
A large reason hyperscale experiences have not yet been sustainably achieved is, in large part, due to decisions made decades ago. A lack of first-principle design led incumbents to build upon existing solutions despite them not being the most optimal for a given problem domain.
Going back to the 80s-90s, computers operated on single processors with single-threaded execution. Then, in the early 2000s, it became possible to execute two threads in parallel. Multiple execution threads could now leverage the same shared memory (RAM) and dramatically increase the amount of compute output.
Progress continued along this track, and it didn’t take long before dual-core and quad-core processors were made available to general consumers. The trouble was that the industry made the very practical decision to continue to abide by the same core “shared-memory” architectural framework.
As society progressed and hardware demands increased, instead of tackling concurrency challenges from a first-principles approach, we just added more CPU cores to a shared memory system.
This shared memory architecture introduces a number of problems that are very hard to overcome. One example relevant to concurrency challenges is the need for constant synchronization across processors in order to maintain consistency and correctness in a simulation.
A way to leverage the superior computational power that comes with parallel processing needed to be achieved without locking all cores to a single shared memory. Over the years, there have been numerous attempts at perfecting what is sometimes referred to as distributed compute to achieve hyperscale. Some attempts have been more successful than others, but none have truly cracked the problem.
Distributed Compute
Below is a non-exhaustive list of many of the most popular commercial distributed compute solutions.
Instancing
Instancing is the most basic optimization method and is currently widely used across many game genres, especially session-based games. It is the process of creating multiple copies of an area, multiplayer map, or entire virtual world – called an instance – to help manage server congestion. Each instance is locked to a specific server, and players can only access and interact with players within their dedicated instance.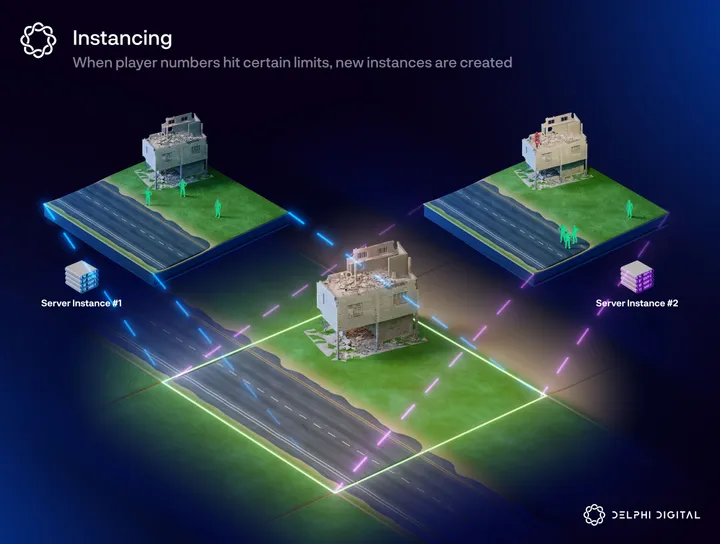
This model works well for session-based multiplayer games with short, objective-based game design (like Counter-Strike or League of Legends) or for larger virtual worlds where developers want to include more independent gameplay systems without sacrificing performance (like MMOs with instance-based player housing, instanced multiplayer dungeons, or specific world servers).
Furthermore, a growing number of backend-as-a-service providers are offering “dynamic load” solutions that aim to aid games with poor server architecture suffering from unexpected levels of success at launch. By dynamically opening new instances, these services can help manage server load and facilitate smoother online matchmaking.
However, instancing does not work well in accommodating very large world sizes or cross-server interactions. Instance-based limitations persist when developers wish to provide an open-world or sandbox virtual environment and introduce more complex game modes.
Additionally, for session-based game modes, matchmaking often requires a set number of players, which can result in long wait times for less popular games. Long wait times often lead to bad reviews, which can put a game on a death spiral.
Zoning
Zone-based instancing, or zoning, is the process of dividing the virtual world into pre-defined, geographically-based zones. Each zone is associated with a specific server, and players transition between servers as they move across zones.
Zoning is an efficient way to distribute server load, which is frequently used in large sandbox games or open-world MMOs, like World of Warcraft, where the feeling of a large living world is integral to the player experience. Depending on the game engine used, a zone can typically host ~100 players.
However, this illusion can quickly break when intuitively obvious systems are made impossible under this framework. Game design decisions must be made to avoid player, AI, or physics crowding, as dense compute scenarios will lead to non-trivial performance degradation and, ultimately, server crashes.
For example, large-scale PvP battles and the bottom-up emergence of player-driven markets or settlements are scenarios that cannot be handled through zoning, and as such, game developers avoid any game mechanics that could lead to these types of spontaneous high-density player-crowding.
Zoning-based games may enable higher single-shard CCUs when player numbers remain within a pre-determined range but become near-unplayable when too many players cluster or log in to the same zone – as seen during the launch of Amazon’s flagship MMO New World. Furthermore, frequently requested features, such as non-instanced player housing or large-scale guild vs. guild battles, are impractical due to technical bottlenecks.
Spatial Partitioning
Spatial Partitioning (SP) is a dynamic zoning framework popularized by metaverse infrastructure providers such as Improbable and Hadean. In an attempt to solve many of the issues prevalent in zoning models, SP (closely related to server meshing and other advanced versions of quadtrees/octrees) dynamically divides a virtual world into a grid of small spatial units (also called tiles), which are then allocated to different servers.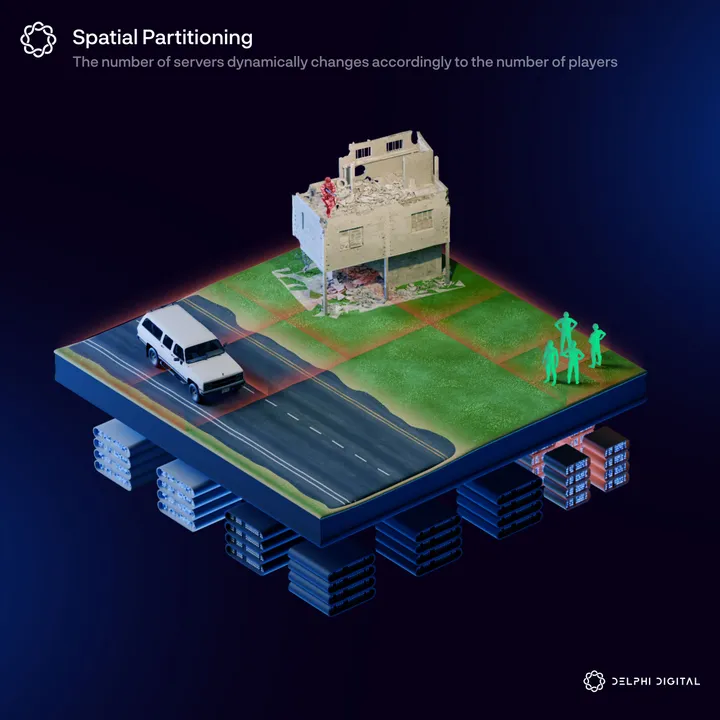
The dynamic nature of SP was designed to be a much more robust solution when dealing with large variances in player numbers compared to instancing and zoning without sacrificing much of the immersion needed in open-world games.
However, in practice, SP features several architectural inefficiencies that make it both costly and arduous for developers to implement while still being subject to fundamental limitations in terms of maximum world size and complexity.
To achieve real-time consistency between players within a shared shard, rapid synchronization must occur between neighboring tiles every tick of the game. As the world size and complexity scale (along with the number of servers), the sync time increases exponentially. Eventually, this leads to a scenario where the sync time is larger than an in-game time-step (a single engine tick), causing severe latency issues.
Game code logic does not naturally include the spatial coordinates needed to operationalize SP. This means that for SP to work, games must be (re)developed from scratch and can require specific coding skills that are abnormal for game developers. It is not possible to port an existing game onto SP network infrastructure. Given long game development cycles, this has severely limited the commercial viability of SP as an approach.
Spatially partitioned tiles are individually a subset of some larger Euclidean world space, and the synchronization and query-processing of this space scales quadratically with the number of players. Not only does this mean that server sync time will quickly scale “exponentially,” but it also almost always results in excess server capacity that must still be paid for, as well as high data egress costs. As the number of server nodes increases at an outsized rate compared to the number of players, server-related operational costs quickly grow to unmanageable levels. This fundamental cost structure makes it impractical to scale and maintain a popular live service game.
Causal Partitioning™
Causal Partitioning (CP) is a novel backend networking architecture developed and owned by MetaGravity. At a high level, CP can achieve a theoretically limitless scale in concurrency by avoiding the typical global synchronization bottlenecks common with alternative solutions, including spatial partitioning. By significantly reducing the amount of data that needs to be shared between servers and clients at every tick, it is possible to reach hyperscale without sacrificing physics, fidelity, density, and gameplay performance.
CP is inherently more cost-effective because instead of processing the entire virtual world for all players at the same time, requiring non-trivial levels of global synchronization, it focuses on the real-time interactions in the game relevant to each user. By decoupling processing from fixed location-based zoning approaches, a CP architecture unlocks significant processing efficiencies that reduce operational costs and energy usage.
MetaGravity has currently tested up to 100k concurrent networked entities (inside a test environment), with cloud costs as low as $1 per user per month (PUPM) – which it projects will scale to 1M+ CCUs at the same unit cost within the next 18 months.
Compare this to Unity and UE’s native 50-200 CCUs at $1-$30 PUPM, Hadean’s one-time record of just over 6k CCUs (and a standard performance of ~1k CCUs) at roughly $10-$20 PUPM, and Improbable’s claimed 1k-5k CCUs at $100-$250 PUPM, which often requires heavy-lift integrations and hard-to-find specialized in-house labor for networking.
Another advantage of this model is that, unlike most other zoning techniques (including SP), which tend to be fully server authoritative, simulations that use CP can more freely distribute authority between the server and client.
This changes the dynamic of what game logic is computed locally on the client vs. what is computed globally on servers vs. what is deemed computationally unimportant and thus not registered. It also unlocks latencies as low as the local client-based simulation allows while still providing the option for server-side simulation, correction, and validation to ensure consistency and security.
That said, teams should be aware that incorporating this tech stack involves several key considerations. A large portion of these are similar to those a team will face when deciding between building a multiplayer game from scratch as opposed to building a single-player game that is then later ported into multiplayer.
Unlike all other previous SP solutions, CP makes it possible to port over a game onto the HyperScale Engine network infrastructure at any stage of the game’s development. However, factors such as game design, client-side APIs, and netcode optimization will all have a knock-on impact on development time and complexity when incorporating CP later rather than sooner. That said, almost all of MetaGravity’s current clients didn’t start development with hyperscale in mind.
MetaGravity is quickly moving into live network operations with clients such as Star Atlas, who have run month-long always-on-beta tests for their community with zero crashes in that time window. This high level of performance is partly due to the principles behind CP but also because the HyperScale Engine has been built in Rust from the ground up, whereas most games technology was traditionally built in C/C++ – which both have a much higher risk of memory safety or security failures. As with any new technology, further testing in real-world scenarios with unexpected and sometimes irrational human behavior will be critical in establishing the architecture’s robustness.
It should be noted that MetaGravity is dogfooding CP as they build out their own in-house MMO called Edge of Chaos. Edge of Chaos aims to be one of the most expansive MMO sandbox games ever built, supporting hundreds of thousands of players in a single immersive open-world environment with high-density environments, complex physics, and close combat gameplay combined with a decentralized player-driven in-game economy.
Finally, although CP’s ability to dynamically adjust client vs. server-side compute unlocks a number of optimization efficiencies, it could also add a number of potential security risks. Typically, any game that features large levels of competitive systems (PvP, PvPvE, etc.) must maintain an authoritative server <> untrusted client relationship unless they are fine providing bad actors with a hall pass. Teams leveraging CP will have to make several key decisions on how much game logic authority they are willing to sacrifice in return for hyperscale while developing more effective anti-cheat mechanisms.
This is particularly true for Open-World MMOs, which are typically run on an authoritative server model. Although this helps to solve many client-side logic security issues, it can come at the cost of scale in the literal sense, as these massive-scale worlds benefit greatly from having a geographically dispersed player base early on. The recent Edge of Chaos community playtest was global, with players participating from 6/7 continents and every major country in a single server instance. Even at these limits, the network performance was very solid, with very few reporting any noticeable lag.
Case Studies
Hyperscale is not a new phenomenon. Ever since the early 2000s, teams have been pushing past the hardcoded limits set by 3D game engines. Importantly, the early days of hyperscale were achieved predominantly through a combination of rigorous and expensive in-house tech development, clever optimizations, and lots of trial and error.
Historic Milestones
Back in 2003, PlanetSide held the Guinness world record for the “most players online at one time in an FPS war game” when it hit 999 players in a single shard. This was later broken by PlanetSide 2, which hit >1,000 CCUs in 2015 during a special event. This was a notable feat at the time, especially for a fast-paced shooter. However, the game became notorious for being near-impossible to run on most average PC hardware available at the time.
Later, in 2018, EVE Online set a new record during a special in-game event dubbed the “Siege of 9-4,” which saw just over 6,000 concurrent players battle it out in the same shard (note that Eve Online has always been a single-server game). One year later, in partnership with Hadean, CCP held a technical demo for EVE: Aether Wars, which saw a total of 10,000 concurrent networked entities (players + AI) duke it out in an epic galactic space battle (both Hadean and Eve Online have yet to replicate a comparably large and dense in-game event).
As a side note, despite CCP developing its entire backend to facilitate a single-server universe, every time one of these large-scale battles occurred, the team had to make a number of concessions to prevent the server from crashing. One such example is how the game’s tickrate would need to slow to a crawl, so instead of lasting hours, these massive battles often lasted for days.
More recently, Thatgamecompany, creators of Sky, were able to sustain up to 4k players in a single instance throughout a one-month special virtual concert. The event was held exclusively on mobile devices and was watched by a total of 1.6M players. This was not the first time the developer had pushed the limits of what was possible when constrained by the mobile software stack. However, the team was still forced to place meaningful constraints on rendering performance during the show, with players on the other side of the concert appearing as little more than blurry blobs.
Spatially Partitioned Failures
For every successful attempt at hyperscale, there have been dozens of failures.
One of Improbable’s first clients to use SP was Worlds Adrift by developer Bossa, a massive-scale MMO. Unfortunately, the game closed down shortly after its release in 2019 after more than four years in development. During an “End of World” stream in the game’s official discord server, the team stated that despite the game being more popular on Steam than they expected, it only sold roughly one-third of their internal worst-case projections and didn’t hit the revenue projections they had set to keep the game alive.
Although Bossa said they didn’t directly blame Improbable’s SpatialOS for the failure, they did state that “creating an MMO like Worlds Adrift is a huge financial commitment.” At the time, Improbable charged a basis of $0.26 per hour for their minimum infrastructure, but Worlds Adrift likely spent much more than this on their custom solution. Importantly, these overheads would have only increased if the game had become more popular and grown its active player base.
Lazarus, developed by Spilt Milk, was the third game (after Automation Games) using SpacialOS to go out of business after spending three years in open alpha. The team stated that “the cost of running and expanding the game… would put a dangerous financial strain on an independent games studio.” Server costs were specifically called out, among others, as a contributing factor to the decision.
MMOs are undoubtedly one of the most cost-intensive genres to develop, regardless of what backend solutions one uses. There is also not enough publicly available information to attribute the failures solely to Improbable and its spatial partitioning technology.
That said, they all join the list alongside Forsaken Legends, Rebel Horizons, Chronicles of Elyria, Mavericks, Somnium Space, and likely more games that were unable to feasibly cover the already high costs of creating large open-world immersive experiences with the high server costs that came with an SP-based backend architecture.
Even Improbable’s CEO Herman Narula admitted that Spatial OS didn’t quite work out as planned and that “high concurrent user technology… is still a real challenge.” The company has now gone on to pivot away from gaming-centric hyperscaled solutions, divesting a number of its entities and investments before expanding to become a part of the MSquared collective and Somnia Blockchain.
MSquared is a metaverse company facilitating large-scale shared 3D virtual experiences. The project has seemingly taken a more hands-on approach, opting to become something akin to a virtual events platform capable of hosting thousands of users within a single shared simulation.
MSquared’s early tests (using its “Metaverse tech stack”) saw just over 1,800 CCUs in a single simulation with little to no complex physics (such as collisions). Another test with Yuga Labs saw 7,200 CCUs, but again, the simulation lacked complex physics in favor of high concurrency and visual fidelity. Yuga Labs later went on to invest in and partner with Hadean before reversing its decision and moving back to Improbable. Time will tell whether a spatial partitioning solution can support Yuga’s ultimate community gameplay objectives.
Early Causal Partitioning Tests
Despite its relatively recent unveiling, CP has already been tested in a number of virtual experiences…
Star Atlas, another blockchain game similar to Star Citizen and Starfield, has been in development since 2020 but recently partnered with MetaGravity to help with scale. In July 2023, a successful 10k CCU test was completed, and by November of that same year, the team was able to scale to 30k CCU (network bots + 200 live players).
This is already a large improvement on the game’s original architecture, which only permitted a maximum of 80 CCU per shard. More importantly, MetaGravity’s CP architecture was able to reduce the game’s server running costs by over 30%.
MetaGravity has also demonstrated CP’s potential in larger scale applications, such as the Beautiful Spaces showcase in partnership with architect Zaha Hadid VR, which saw 100k networked bots interact at the same time with full collisions within a relatively simple yet high fidelity room, and a Gaming Hub application built to support >75k networked bots in a shared virtual environment.
Wilder World, a blockchain gaming company building a GTA-like open-world sim, partnered with MetaGravity to help power their virtual world and 10k CCUs within a single shard (with a short to medium-term goal of reaching 30k CCU). 
In addition to the early tests with 10k networked bots and over 200 networked vehicles (referencing the ten facets of hyperscaled virtual environments available in the notes, vehicles require more complex physics, and thus the density of concurrent vehicles was reduced in order to maintain the high level of visual fidelity), the team was also able to scale their map to 13.5 times the size of GTA5 and reduce its cloud computing costs.
Making Network Engineering Accessible to any Developer
Leveraging a CP backend architecture to achieve hyperscale at a fraction of the cost of the SP counterparts is only half the story. The other half is in how this technology is packaged and made available to developers.
Although SpatialOS and Hadean relied on an architecture that proved to be structurally inefficient, there were other flaws that played a role in causing so many of the games using it to encounter significant challenges. Aside from the huge server overheads incurred, SP-based solutions have been prone to network outages and historically have been very labor-intensive in integrating into traditional game development workflows.
Both Improbable and Hadean required developer teams to rewrite a large portion of their backend stack (entirely replacing almost all networking code). Combined with the fact that the skill set required to integrate and manage such a server architecture is in short supply, made this approach particularly impractical – especially for smaller teams and independent developers.
Experienced gaming-focused network engineers are in incredibly short supply. As such, it is not unusual for service providers to allocate dedicated support staff in the lead-up to launch. As previously stated, due to the fact that SP, by definition, required a game development studio to write gameplay code with the native spatial coordinates built into the game logic, it was impossible to port over a game that had already been built. It also required a co-dependent relationship with your technology provider above and beyond typical standards, as any small update or new feature could often lead to engineering bottlenecks that took game designers away from where they were most needed – designing fun games.
Causal partitioning was created to be as simple and easy to use by design for any game developer familiar with multiplayer game code. CP still replaces a game’s server architecture but does so in a way that minimizes friction compared to alternative solutions. The goal is for this process to become as easy as any standard multiplayer game development, allowing developers to remain backend-agnostic and not requiring sophisticated network programming skills.
Integrating CP will not need any deep netcode expertise, allowing developers to maintain focus on client-side gameplay and bog-standard multiplayer networking code (be it developed in-house or using third-party providers).
Competitive Landscape
Moving past the technical nuances of distributed compute and scale, the following section will briefly compare the current offerings within this sub-sector, as well as examine where they fit in the broader backend-as-a-service competitive landscape.
The graphic below illustrates eight service providers that all operate within the same broadly defined sector of distributed computing solutions. It is important to note that there are very few “apples-to-apples” comparisons operating at the intersection of distributed compute and hyperscale.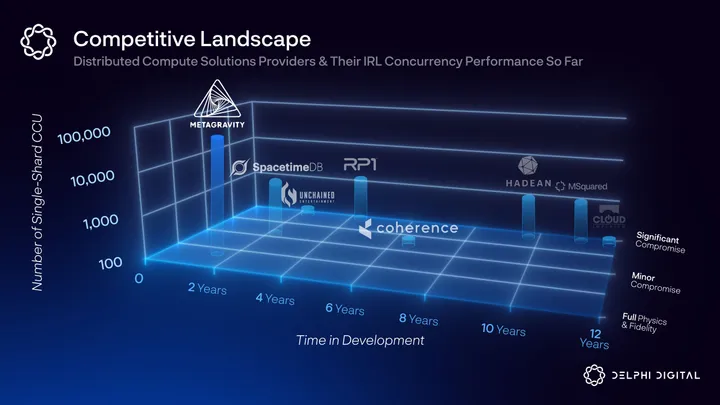
Looking at the “old guard” of SP-based providers, MSquared (formerly Improbable) has pivoted into a virtual events platform, which is still limited by its current infrastructure and requires tradeoffs on physics. Hadean hasn’t announced a new gaming partnership in over a year (and is believed to be focusing more time on its defense business going forward). Cloud Imperium is >10 years into developing Star Citizen and still only optimized to handle 100-200 concurrent players, and RP1 is focused on low-fidelity XR and browser-based experiences.
Unchained Entertainment, previously City State Entertainment, first raised funds in 2013 and recently relaunched one of its games, Final Stand: Ragnarok, in Steam early access to help test its new MMORPG game engine. Unchained’s aim is to compete directly with incumbent game engines such as Unity and Unreal Engine and optimize client-side compute in order to scale density. Moreover, all publicly available information suggests that they are constrained to the same backend bottlenecks as other SP techniques, limiting their total player count to the low thousands (current tests maxed out at ~500 CCUs).
Another new entrant, Clockwork Labs, is taking a novel approach to its architecture. Creators of Spacetimedb: this team developed their tech stack while building out their first game, BitCraft, and are blending the server and database into one in order to simplify networking and leverage more than 50 years of research on databases. Notably, early pioneers in hyperscale concurrency, CCP, took a similar approach to Eve Online’s backend architecture (CCP’s CEO Hilmar Pétursson is actually an early investor in Clockworks Labs). All that said, early alpha tests have peaked at ~700 CCUs, placing Spacetimedb at the lower end of the scale spectrum.
Coherence uses a technique called “dynamic clustering,” which sounds similar to previous SP approaches, such as those employed by Hadean. However, the company’s core focus is as a single-player to multiplayer backend migration service. The fact that its proprietary networking/client <> server synchronization efficiencies enable “hundreds to thousands” of single-shard CCUs is a feature rather than the core product.
Others, like Planetary Processing, appear to adopt the same technological approach as Improbable, albeit with a better onboarding experience, but tailor its services toward indie developers who are less likely to encounter the same game-killing unit economics large amounts of CCUs produce (but at the same time not providing a way for developers to “opt-out” in the case that their games become breakout successes).
MetaGravity stands out by offering a fundamentally different technological approach compared to most existing solutions. Internal development attempts to solve the concurrency scale issue (i.e., Roblox and Star Citizen) will continue until the industry reaches a consensus that there is a new technology that delivers on its promises. A buy rather than build decision in this regard would help to avoid costly and lengthy internal development projects.
There remain opportunities for novel approaches, but ultimately, the technology that delivers on the promise of hyperscale first, and at a commercial scale, will be the one that defensibly captures the most market share. When game developers see the technology in action in a live environment, most studios will choose the technology that performs the best (in terms of hyperscale), offers the most attractive compute economics, and is the easiest infrastructure platform to deploy.
With that in mind, current performance is a stronger indicator of future growth than any development roadmap. MetaGravity has spent less time in the market (not including the team’s decades of experience) but has already managed to outperform all of the competition in terms of sustained CCU within a test environment.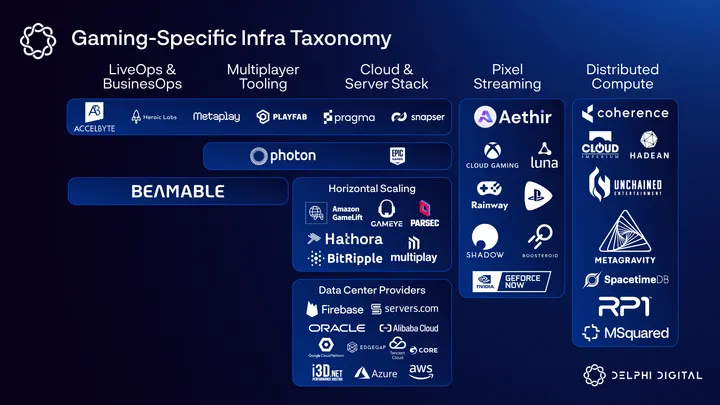
Zooming out, the importance of market positioning and mindshare becomes more apparent when you look at the landscape of multiplayer backend-as-a-service solutions providers as a whole. Whereas MetaGravity’s core value proposition is its causal partitioning tech stack, others compete on a broader scale and offer a multitude of multiplayer-adjacent services. The below visual is a high-level depiction of gaming-specific infrastructure that competes within the same attention economy.
Briefly, we define “Backend Software Services” as being low-lift integrations typically facilitated by APIs/SDKs. “Platforms/Engines,” on the other hand, allow for more granular customization from game developers in exchange for being a heavier-lift solution. Zooming in on each vertical, in addition to “Distributed Compute,” which contains all of the previously mentioned competitors, there are:
- “LiveOps & BusinessOps,” which include tools that aid in the management of live service games, such as analytics dashboards and player support.
- “Multiplayer Tooling,” which is broadly defined as including any baseline services for multiplayer games, such as matchmaking and leaderboards.
- “Pixel Streaming,” which enables easy deployment of games with optimization for rendering across multiple device types
- “Cloud and Server Stack,” which is comprised of bare metal and cloud data centers, relay networks, databases, peer-to-peer or client-to-server etc.
It is important to note that many of the core infrastructure providers listed in the above graphic should be viewed as potential partners rather than direct competitors to the more niche service providers, such as MetaGravity. Server infrastructure providers like AWS, Azure, Tencent Cloud, and Google Cloud Platform, in particular, host a large portion of the world’s gaming-dedicated server infrastructure – infrastructure that is leveraged by many of the other “competitors” within that vertical.
There are, however, service providers that span multiple verticals in order to position themselves as all-in-one solutions. Companies like Heroic Labs, PlayFab, Photon, and Epic Online Services (in partnership with EdgeGap) maintain a majority market share for multiplayer backend services across all platforms.
Some of these market leaders may aspire to bleed over into hyperscale concurrency, as hinted at by Epic’s new server replication system called Iris. However, most of these initiatives, including Iris, are focused on making architecture optimizations rather than novel technologies and can only scale single-shard concurrency so far. These same incumbents are often crippled by a backend architecture that is unconducive to achieving hyperscale.
Recently, Epic CEO Tim Sweeney stated in an interview with Matthew Ball that the reason that Fortnite Battle Royal is limited to 100 concurrent users is because “we couldn’t make it work for 200 players on a server [because] computers in the data centers were too slow.” He also stated that the current version of Fortnite will, within the next seven years, be viewed as an “artifact of the limitations of the current technology that we’re working within.”
It is possible that some may try to improve their backend network performance like Epic did with the release of Verse, the new scalable programming language behind Fortine Creative 2.0. However, due to the networking complexity required to pursue a more first-principles approach to redesigning distributed compute architecture, it is unlikely any of the multi-vertical incumbents will attempt to deliver on hyperscale while the execution risk remains high.
With this in mind, while the largest incumbents compete for mindshare as general-purpose multiplayer backend service providers, there remains an opportunity for newer entrants that tackle industry problems in innovative new ways and remain free from technical bloat. With a specific focus on hyperscale, MetaGravity’s tech stack can maintain a competitive advantage in terms of proven performance when compared to all other direct competitors.
Ultimately, we see all or most multiplayer games wanting to use the network infrastructure, which delivers the best performance at the lowest cost and is the easiest to deploy and operate.
Qualitative Insights
Moving on from the supply side of the future of scale equation, we attempt to better evaluate the demand side by conducting a series of qualitative interviews with industry-leading developers who have created and shipped games for more than 30 years, including titles such as Ultima Online, Eve Online, Star Wars Galaxies, EverQuest, and many more.
Throughout these conversations, three clear themes emerged in regard to what game-specific technical innovations these developers are most interested in and what they feel is an ideal level of hyperscale.
Note that out of the developers interviewed, only one had experience designing games for more than 5k CCUs in a single shard, and the majority were currently developing games within a single genre, MMOs.
Theme #1 – Costs & Dependencies
All respondents noted that a key constraint for teams of all sizes is the costs associated with scaling simulations. This can be broken down into operational costs and dependency-related costs.
The operational compute costs associated with scale are widely recognized. All traditional distributed compute architectures result in an increase in server demand as a simulation scales. Most service providers offer some degree of dynamic scale so that servers can be added and removed in line with the ebbs and flows of CCUs. This is so that a large excess of unused servers aren’t paid for, but there is still a meaningful amount of wasted space due to the fundamental flaws of traditional server architectures. As illustrated by Improbable’s early partnerships, the more ambitious a game aims to scale its player base, the more likely the costs will put them out of business.
The dependency costs are more opaque and can be broadly broken down into two aspects, the first of which is not exclusive to distributed compute providers. Multiplayer services providers hold a meaningful amount of leverage over small- and medium-sized teams that rely on them for most of the basic features expected in multiplayer titles.
Matchmaking and leaderboards may sound simple, but many teams opt to outsource these features to third parties so they can focus on the fun of game development. This then creates great dependencies on their service providers, as a game can quickly become unplayable when one or more of these services break. Moreover, if put in a situation where a change in service provided is necessary, many teams end up incurring higher costs to port to a new partner than they would if built in-house. Nowhere is this more evident than in the closure of Amazon’s Gamesparks, which was a core inspiration for why projects like Beamable decided to decentralize their backend services model using blockchain technology.
The other side of dependencies is more technical and labour-specific and applies to games that want to take full advantage of what is possible today with hyperscale solutions. Good gaming-specific network engineers are in short supply, and many (not all) of the distributed compute solutions on the market today require some level of custom netcode. This has resulted in most service providers sending engineering teams to help game developers with multiplayer game development and technical integrations.
Not only does this add additional upfront costs for developers, but it also creates non-trivial dependencies when errors occur or when custom modifications are needed. This fact alone can often be a non-starter for teams that don’t want the headache of outsourcing bottlenecks or are unable to hire in-house specialists. Herein lies the market opportunity for a third-party networking solution that can provide the benefits of hyperscale at low operations cost and development complexity.
Theme #2 – Horizontal vs. Vertical Scale
When asked whether they valued vertical scale or horizontal scale more, the respondents were split in their answers. It should be noted that in this context, vertical scale refers to the amount of compute added to an existing server and is usually associated with more dense and complex gameplay. Horizontal scale, on the other hand, refers to the amount of compute added across multiple servers, which is generally associated with things like increasing the total size of the virtual world.
Some stated that despite a relative increase in compute capabilities derived from improvements in cloud computing and decentralized compute offerings, they still felt constrained by the amount of vertical compute they could access without degrading the player experience. These respondents would happily squeeze every last drop of compute budget in order to increase game design complexity and minimize latency.
Other respondents expressed excitement about what can be achieved by scaling horizontally as opposed to vertically. Enabling emergent play patterns throughout vast, immersive environments that are both seamless and persistent. Importantly, it was also noted that in order for these worlds to feel exciting, a level of vertical compute will be needed to scale density to populate these worlds with procgen intractable objects, autonomous AI NPCs, and hopefully crowds of players.
To follow on from this point, all respondents agreed that seamless worlds were much more exciting than “large crowds.” To this point, regardless of what new technology can enable, clever game design that takes into account how players want to interact with virtual experiences means more than just lifting all constraints and fitting more “things” onto one screen.
Not a single respondent was excited by the prospect of more than 100k users packed inside a single shared world. In fact, all believed that more than 10k CCUs interacting on a regular basis would detract from the player experience in existing frameworks of game design. One respondent pointed out that “good fences make good neighbors,” – referring to how instancing or zoning often created engaging social dynamics between server groups in games like World of Warcraft. Another noted this as “not really a technical problem, but more of a social one.” Bringing thousands of players together is a logistical nightmare, and the majority of games will never be able to make players care enough to attend in earnest on a regular basis.
Although hyperscale in terms of density was felt to be less important, respondents were all excited by the prospect of having vast open worlds with little to no walled gardens. Furthermore, respondents pointed out instances where player density can add to the gameplay experience. Flashcrowds of thousands of players, for example, can often be a great form of emergent player behavior that is technically challenging to facilitate with traditional backend architectures that struggle to scale both horizontally and vertically.
Theme #3 – In-House vs. Outsourced
One developer believed that a hyperscale concurrency solution still felt far from being commercially viable at the time of writing. Consumers (game developers) either don’t care enough about >1k concurrents and will settle for less, or they will care so much about it that they will still try to build the necessary technology in-house to meet their specific needs.
This is especially true for MMOs, which have historically struggled to find holistic backend solutions that can survive in the long term. Eve Online, Final Stand: Ragnarok, and Bitcraft are all examples of games that were specifically designed around hyperscale as a feature and chose to try to build the necessary tech in-house due to the belief that there were no viable platform alternatives on the market.
It is undeniable that the number of effective third-party concurrency-focused backend solutions continues to be limited. This is not helped by the fact that the games that have seen outsized levels of public interest have later had their viability questioned.
That said, as soon as a cost-effective, easily integrated, battle-tested solution is available on the market, all respondents noted that it would excite them about the future of the multiplayer games industry.
Conclusion
As the wider gaming market continues to be challenged by increasing competition, growing budgets, and a changing technological landscape, more developers will need to optimize their backend systems, double down on their core competencies, and outsource wherever it makes sense in order to remain competitive.
In addition to the adoption of AI game development tools and the democratization of key parts of the backend stack – which all allow smaller teams to accomplish more – the propensity for game developers to choose to buy versus build is likely only going to increase over time. This not only saves costs but also affords teams more time and resources to focus on delivering novel and superior player experiences that help them stand out from the competition.
With this in mind, service providers that can meaningfully reduce costs or facilitate the unlocking of new net experiences at comparable costs to traditional server providers are well-positioned to be a driving catalyst for growth.
In addition to the operational benefits that could materialize with hyperscale innovations, the unlock of truly large and seamless open worlds, content-dense cities, and high-fidelity persistent environments will help usher in the next wave of metaverse experiences.
In the short term, some developers may limit the use of hyperscale technologies to large-scale player battles held as seasonal events. Although some believe that these infrequent occurrences of real-time crowded thousand-player battles are just novelties, they will undoubtedly lead to meaningful changes in game design that facilitate these spectacles as opposed to outright avoiding them (as is the case today due to the technical constraints).
Over time, we will likely see wholly new gameplay models materialize from this less restrictive building environment. A sentiment shared by Tim Sweeney, who, when talking about why hyperscale seamless worlds should scale into the millions of CCUs, said, “That’s got to be one of the goals of the technology. Otherwise, many genres of games just can never exist because the technology isn’t there to support them.”
However, whereas Epic is working to get Fortnite ready for that eventuality within the next seven years, MetaGravity aims to unlock 1M+ CCUs within the same server shard in the next 18 months.
Provided all near-term development milestones are reached, which is likely given the rapid performance improvements that MetaGravity has already delivered, we can envisage the following three-stage roadmap for the advancement of the CP approach in the next few years:
- A short-term focus is on bespoke integrations due to a general lack of specialized labor/understanding in the developer market. MetaGravity is currently providing professional services integrations into its HyperScale Engine network infrastructure, which allows for parallel game development and reduces dependencies on outsourced networking solutions providers that can quickly add bottlenecks on development and troubleshooting.
- A mid-term focus is on ecosystem scale by providing plug-and-play style SDK and API templates in Unreal and Unity for teams to experiment with and pay per use. Given the need to convince studios of the power of CP after the limitations of SP, note that if this step is introduced too early, they run the risk of allowing teams to attempt to cut costs but ultimately produce sub-par products, which could hamper the adoption of the technology.
- In the long term, the platform technology will have developed to a point where many of these integration solutions can be frictionlessly and potentially fully autonomously implemented.
The poor past performance of historical scaling solutions has led many to be skeptical about what hyperscale can truly bring to both the developer and player experience. However, too much skepticism is not conducive to innovation. As soon as there are breakthrough public case studies on the power and viability of new technologies, game design innovation will accelerate.
It is hard to predict what that breakout success will be. Maybe it will be a hyperscale MMO like Edge of Chaos, Project Awakening, or Stars Reach. Maybe it will be social gaming hubs, guild halls, or entirely virtual esports arenas that bring together thousands in a persistent virtual experience.
We’ve also only just scratched the surface with the emergence of a select few successful Massive Interactive Live Events (MILEs) like Twitch Plays Pokemon, Reddit’s r/Place, GTA: San Andreas Run, and Neflix’s Squid Game. Technical constraints have always limited these experiences to 2D interfaces, but the emergence of better scaling solutions, like CP, will allow even bigger MILEs to exist in persistent 3D environments.
Gaming has always been at the forefront of technical innovation as pioneers are not restricted by scientific bureaucracy but instead by their ability to inspire and entertain. We hope that the next wave of backend server solutions will reduce technical dependencies, maximize cost efficiencies, and ultimately empower developers to build better games.
Extra
The 10 Facets of Hyperscale
Enabling many thousands of CCUs to interact within a single shard is a component of any would-be hyperscale experience. However, as illustrated in some of the previously mentioned case studies, that alone is not enough to increase a game’s chances of success.
Similar to how bad game design cannot be disguised with great graphics, hyperscale experiences need more than lots of players. Specifically, outlined below are ten core facets that have a direct impact on the user experience in hyperscale virtual worlds.
Graphical Fidelity:
Some would argue that a fully immersive virtual experience can only be achieved if graphical fidelity remains equal to, or better than, the best-looking games available at the time. Note that fidelity is not the same as art design. The point is not to place creativity constraints on developers but instead to ensure that scale does not inflict limitations on fidelity.
Great game design may not be reliant on good graphics – Roblox is a great example of this. However, for a virtual world to become widely accessible and deeply immersive, “good enough” levels of graphical rendering must be maintained across a multitude of different devices.
Entity Density:
In tandem with concurrency comes density. What good is a world with hundreds of thousands of players, intractable objects, and AI if they are forced to remain sparsely dispersed across a large and uninhabited world? A sense of density is integral to any virtual experience that aims to fully immerse players.
Bearing in mind one of the key themes mentioned in qualitative interviews with game developers – “crowds are annoying” but “flashcrowds can be great” – smart game design decisions should be made to balance a sense of liveliness with overpopulation.
Whether in a village or a city, high-demand facilities like a bank or marketplace should feel more densely populated than suburban non-instanced player housing or a country road. Furthermore, virtual worlds should be able to facilitate dynamic changes in density to reflect the ebbs and flows of a typical habitat.
Physics complexity:
One of the most common shortcomings of most attempts at creating hyperscale virtual experiences is a lack of complex physics. Omitting player-to-player collisions, for example, makes scaling concurrency much easier but limits immersion.
However, once again, true immersion cannot be achieved when taking shortcuts. The end-state of hyperscale requires not only the typical physics seen in real-world environments but also the ability to simulate the physics expected in sci-fi space stations, demonic dungeons, or magical municipalities.
Additionally, immersive worlds must one day facilitate thousands of autonomous AI NPCs and an infinite number of persistent player-to-object interactions. Whether it be through non-instanced player housing or a vast battlefield with destructible environments, players should be able to interact with these worlds, and these interactions should be forever shared between all players.
World Size:
Immersive virtual experiences must allow for seamless traversal throughout the world. As mentioned numerous times, these worlds will only get bigger. Importantly, seamless traversal should not compromise any of the other facets on this list.
In terms of single-world simulations, Minecraft already allows players to travel throughout a sandbox spanning 1.5 billion square miles, but the low-fidelity voxel world lacks density and complex physics – not to mention that the multiplayer server size is severely limited to 100s.
What if interplanetary travel is possible? Starfield is comprised of 1,000 planets, and No Man’s Sky has 255 freely explorable galaxies. Both, however, suffer from having a large percentage of planets feel completely empty or filled with the same templated environments.
Player Agency – Themeparks vs. Sandbox Experiences:
The difference between theme parks and sandboxes is an important factor in determining the true level of hyperscale an open-world virtual experience provides. A theme park game is loosely defined as a linear story where the game developers hold the player’s hand through an open-world adventure. Sandboxes involve very little handholding and facilitate entirely autonomous and emergent play patterns (note that there exists a common medium between the two called sandparks).
The nuances between these two game types are important for hyperscale because persistent open-world sandboxes are some of the hardest games to create and sustain. This is because, in order for them to feel truly immersive, they must be able to support highly interactive and dense multiplayer environments that remain consistent across different clients. This can only be achieved at a high degree of quality using an optimized hyperscale architecture.
Real-Time:
The real-time problem can be described as if player A shoots a gun at player B by time x; then all players should see A shoot B at time x.
Real-time problems require servers to confirm the action before pushing a queue of messages to the client. This is fine in instanced-based games where real-time problems can largely be solved (there will always be some lag) with predictive modeling (e.g., Dead Reckoning) and lag compensation.
There is also research outlining the benefits of zoning and interest management in solving real-time issues in larger-scale games, showing that issues become unnoticeable when player-to-player interactions occur within the same zone. However, these tend to break down as concurrency scales and/or a multi-zoning approach is implemented.
When the game state for all entities within an area of interest across multiple zones must be synced to the server and then back to all relevant clients at every tick of the game, lag and consistency problems quickly emerge that break down player immersion. A common example of this is referred to as the sniper problem.
These problems can be largely solved by omitting location-based spatial partitioning in favor of a causal-based approach. That way, instead of all data being synchronized across all servers and clients, only the relevant entities need to be included in the data transfer, saving compute resources.
Consistency:
A crucial component of any multiplayer virtual experience is consistency. Consistency in this context ensures that changes in the game state (i.e., player/AI actions, changes in the environment, interactions between players/AI, etc.) are reflected the same way in every relevant client.
This is particularly important when one player’s actions can impact another’s reality. To solve this, a typical server architecture, which leverages single-threaded processing, will tell a central server to arbitrate all client -> server messaging to ensure that all servers/clients receive the same messages in the same order.
As shared virtual worlds scale and more server nodes are implemented to accommodate additional players, consistency can begin to show signs of strain. Maintaining a real-time simulation across multiple clients with varying degrees of latency can quickly cause processing bottlenecks.
Historically, consistency challenges have been handled with clever game design. For example, in World of Warcraft (and many other fantasy MMOs), in order to proactively avoid potential issues, the game implements a spell-cast timer (a brief charge period before some spells can be cast). This makes it easier for the servers and players to recognize who cast first and who got hit first.
Importantly, more scale introduces more problems, and SP-based architectures, due to the consistency models they adhere to, are forced to remain tied to server-side compute only. This is impractical for fast-paced, competitive multiplayer titles that would quickly break under such a server dictatorship.
CP, on the other hand, facilitates a more flexible distribution of server and client-side computing to more closely resemble traditional FPS models where certain interactions are computed client-side.
Latency:
Latency is essentially the time it takes for data to go from a user’s client to the server and back again. A delay, or lag, in this data round trip can be inconsequential in an open-world RPG, where it might only result in a slight delay in player-to-player communication. However, it can have significant implications on the player experience in faster-paced titles, like a competitive FPS, where it is the difference between kill or be killed.
Latency is fundamentally constrained by the speed of light. That said, variances in human-made infrastructure (broadband networks, data centers, optic fiber cable networks, etc.) mean that latency rarely achieves maximum velocity.
Incremental improvements have been made with the proliferation of cloud edge node infrastructure – placing smaller local cloud servers in edge locations. This helps minimize latency but is ineffective in regions with poor server infrastructure.
In order to handle variances in latency between clients to ensure consistent gameplay in fast-paced competitive multiplayer genres, backend techniques, such as lag compensation and interpolation, have been designed to vastly improve the user experience.
Depending on the genre, these techniques are table stakes for hyperscale multiplayer experiences and should be made optional by the backend service provider or, at the very least, allow for easy integration with third-party solutions.
An alternative model for reducing latency-based challenges is to limit the need for server <> client communication. By reducing the need for constant server synchronization, developers can reduce the number of times a client is subject to latency. Note that this model is better suited for relatively slower-paced open-world games.
Persistence:
Most of the above-mentioned facets of hyperscale experiences only become relevant when persistence is introduced. In games where there is little need for player progression, meta gameplay, or lasting immersive experiences, there is little need for data synchronization and storage.
This may be possible in some roguelites or casual games of chess, but for all other live service games or games that wish to obtain forever game status, persistence is table stakes. With this in mind, the challenge then becomes how to maintain persistence while minimizing the need for constant server synchronization.
Games leveraging SP have historically struggled with this while maintaining a cost-effective backend – Cloud Imperium and its game Star Citizen are still struggling to integrate an optimized replication layer that saves all game states across every entity in every zone without this costly server architecture from causing the game to constantly crash.
The team at Spacetimedb believes that everything should be considered a database and has designed their backend solution to do just that – merging the server and database into one. It is still too early to state with any certainty how this model scales, but it is certainly optimized for persistence over all else.
The CP model, on the other hand, is much closer to a traditional game design approach where the focus is placed on optimizing what data should have synchronization priority (more of a game design decision) and when it should be synchronized.
In games that rely on fast-paced gameplay, each causal domain (the dynamic area that contains all causally related entities) is duplicated in real-time. Each duplicate runs in the background until there is a significant divergence in the state, at which point the causal domain is synched to the servers, optimizing compute resources and minimizing latency spikes.
Note that this approach also alleviates many of the challenges in avoiding many of the real-time problems previously outlined.
Cost:
Finally, it is important to note that a viable cost assumption should be made for all of the above facets.
It is one thing if teams can achieve all of the above with an unlimited budget. However, the real industry will occur when access to these solutions is not cost-prohibitive. This also applies to labor and time costs. The simpler the integration, the greater the adoption curve.
Decentralized in-game economies are only going to be possible in the multiplayer open-world games of the future if the costs of operating the network infrastructure are affordable and can be paid for directly by the in-game economy. This is only ever going to be possible with massive compute efficiency gains and a move to the lowest cost, decentralized network infrastructures.
0 Comments