Pyth Takes on Oracle Sector Dominated by Chainlink
When people think of oracles, they think of Chainlink, and for good reason. A darling from the 2018-19 bear market, Chainlink is the most well-known and used oracle today, securing ~$12B across over 200 protocols, the majority of TVS (Total Value Secured) being Ethereum lending protocols Aave and Compound. These two lending protocols make up just over half of Chainlink’s TVS alone. Pyth is a new player who started last year with a focus on Solana and, more recently, is looking to branch out.
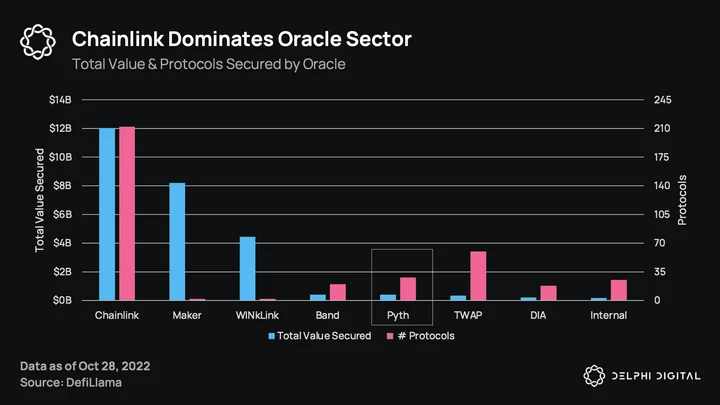
With Chainlink so integrated throughout DeFi, a natural question would be why do we need another oracle? Besides filling the oracle need on Solana, Pyth takes a fundamentally different and innovative approach to oracles, getting information only from first-party sources, without the use of data aggregators in the middle. While other oracles like Chainlink do have some first-party run nodes, they also rely on aggregators (e.g. CMC, CoinGecko) as part of their process. Pyth also introduces the concept of confidence intervals, a tool that gives protocols more information about not only price, but price uncertainty, particularly in times of high volatility/low liquidity.
{kind=link}
What Makes Pyth Different?
Only a small group of users have access to timely and material market information. These are trading firms, market makers, and exchanges. Pyth has these participants publish prices directly to Pyth themselves, thereby removing the costs that come from data aggregation and significantly reducing the latency from off-chain price discovery to on-chain reporting, leading to more-timely and higher-quality prices. Many of Pyth’s publishers are well-known, from crypto entities like Amber and Wintermute to TradFi entities like Jane Street and the Cboe.

Pyth takes prices from individual publishers and aggregates them. However, instead of publishing a single price, they publish a price within a confidence interval (CI). For assets that trade on various venues with different participants, information, deposit/withdrawal limits, liquidity profiles, etc., there is no such thing as a “true” price. Using confidence intervals over a single price can reflect a more realistic state of the market and current liquidity conditions, particularly in times of high volatility.
While this process demands additional considerations from DeFi protocols, it does offer some advantages. To illustrate, say the aggregate price of ETH is $1,500 +/- $5. To get a price with a 99.7% probability of being true (assuming correct normal dist. estimates), multiply the CI by 3. This would give a very high probability that ETH’s true value is between $1,485-$1,515. Protocols can choose which level of conservativeness/aggressiveness they’re comfortable with by determining their own CIs. For example, a conservative borrow/lend protocol may value collateral at the lower end of the range ($1,485), reducing the amount users can borrow when taking out a loan. Alternatively, a more aggressive lending protocol can value the collateral at the higher end ($1,515) to avoid unnecessary liquidations.
In normal market conditions, CIs should be tight (ETH is usually <$0.50). During abnormal conditions, CIs need to be considered and planned more carefully. Using confidence intervals allows for more exotic products, for instance, Zeta Markets’ use of CIs to generate settlement prices less susceptible to price manipulation around expiry.
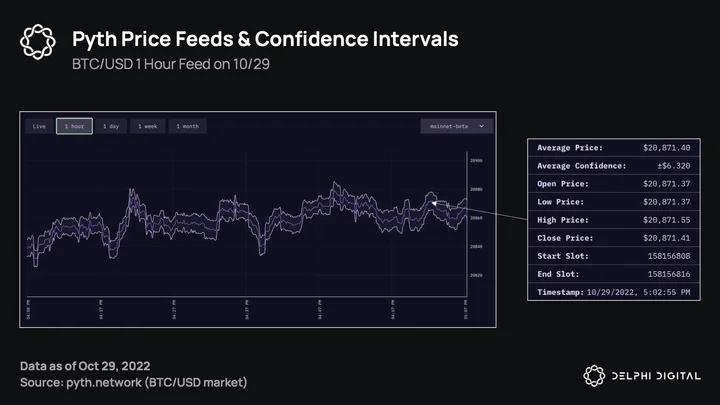
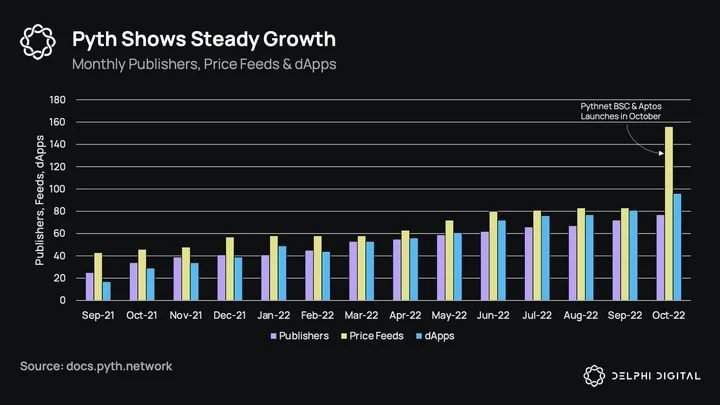
Since Pyth went live last year, it’s seen steady adoption on Solana, and has been the de facto oracle on the network — covering nearly the entire ecosystem. YoY growth has been as follows:
-
Publishers: 25 → 72
-
Price feeds: 43 → 83
-
dApps: 17 → 81
Early Growing Pains
Pyth had some issues early on that hurt their reputation. We’ll touch on what happened and why, and then get into the details of how the Pyth engine works and the steps to mitigate these occurrences in the future.
The first major issue was around the BTC/USD price for a 2-minute period on Sept. 20th, 2021. Due to 2 out of 11 publishers making a decimal point error and the aggregation logic overweighting their contributions, the aggregated price ended up being significantly off BTC’s true price of ~$42k, reporting prices as low as $5,402 with confidence intervals of +/- $21,623. This error led to useless (and dangerous) price info. For protocols that didn’t incorporate the confidence interval, and simply relied on the median price of $5.4k, this resulted in detrimental effects such as erroneous liquidations.
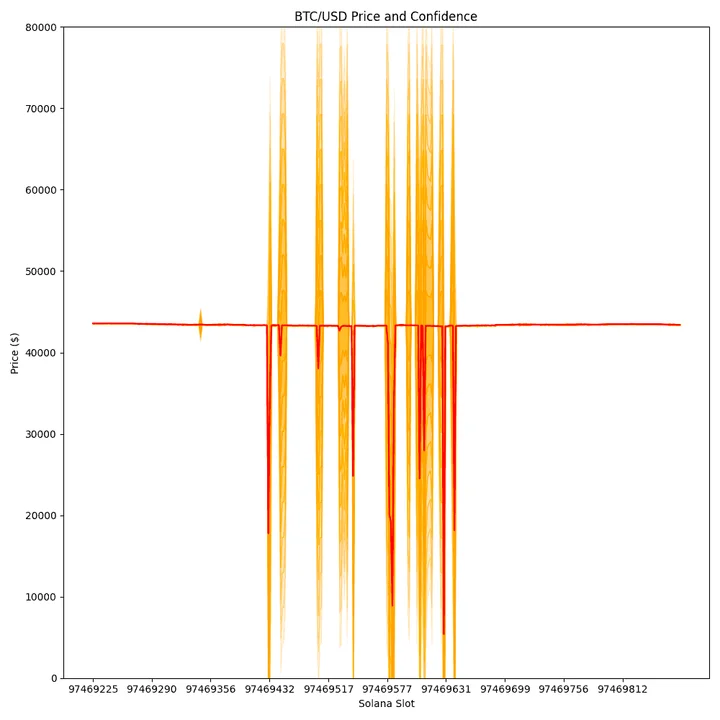
This event would lend credence to oracles using aggregators. You can make a clear argument that data aggregators would not have reported such prices, as it is their job to remove outliers like this. This is a tradeoff to not using aggregators; by removing middlemen, and the costs that come with them, you can have faster and (potentially) higher-quality updates. However, if the algorithm or stake weighting doesn’t properly account for outliers like the above, you run into serious issues. This filtering/aggregating process in the middle is a check that Pyth doesn’t have, instead relying on crypto-economics (later in report) and algorithms. So, what were the remediation steps taken by Pyth here?
-
Developed a testing protocol with better onboarding for new publishers.
-
Adjusted the aggregation logic to properly weigh prices that span such a large range (discussed in detail later).
-
Created enhanced documentation for developers on how/why/when to use the prices intervals. As mentioned before, this is a more involved process for protocols, and many are not used to the concept of CIs, instead just taking the median as they would with another oracle.
-
Onboarded more publishers: BTC/USD now has 30 publishers, vs. 11 when the error occurred.
-
In the future, crypto-economic security by stake weighting and slashing with the PYTH token.
There were also a few other early issues, like a software bug that reported a negative TWAP, Solana network congestion resulting in stale and less-diverse price updates (which is hard to blame Pyth for), and some other extremely-wide confidence intervals like the BTC issue on illiquid/poorly covered markets. While protocols have some responsibility in understanding how to use Pyth’s data and confidence intervals, reporting of erroneous prices is obviously not acceptable for an oracle. Additionally, having median prices & CIs so detached from reality is a liveness failure in the best case and financial damage in the worst case.
With all that being said, Pyth has been much more reliable since these early issues, especially as their coverage (# of publishers) has expanded. It’s also important for us to distinguish between what is an actual oracle failure, like the BTC issue above, and what is market manipulation, like the Mango or Solend attacks more recently (note that Pyth was not involved in either regardless). Oracles should be judged on whether their prices reflect the true price on exchanges. Illiquid assets with shallow markets are susceptible to manipulation, and protocols need to be stringent when underwriting and setting risk parameters for them. Since the Mango attack, we have seen other protocols like Compound delist some of these illiquid assets as a preventative measure, and this is also a situation where widening confidence intervals or using a TWAP, SMA, or EMA could help mitigate negative outcomes. Pyth has also started doing more work around the concept of Liquidity Oracles, incorporating an asset’s liquidity into the underwriting process and thus adding the market impact of selling the collateral asset into the max-borrow formula. The goal here is to prevent users from creating positions that are too large to liquidate.
Creating a publisher-first oracle from the ground up is challenging due to low market coverage at the start, and publishers may not want to onboard due to technical or reputational risks before the network is mature. Over the past year, Pyth has started to overcome this cold start and continues to onboard reputable publishers. Besides a better onboarding/integration process and documentation, they’ve made material changes to their price aggregation algorithm and, in the future, will be adding another measure with crypto-economic security around their upcoming token PYTH. They’ve also recently launched their solution for non-Solana chains called Pythnet, a fork of the Solana codebase as a standalone chain. We’ll now get more granular into how this all works.
How the Pyth Engine Works
Before we start, we should note that some parts of this model (like delegator staking and data fees) will not be live until the PYTH token is launched (you can lurk here for potential updates).
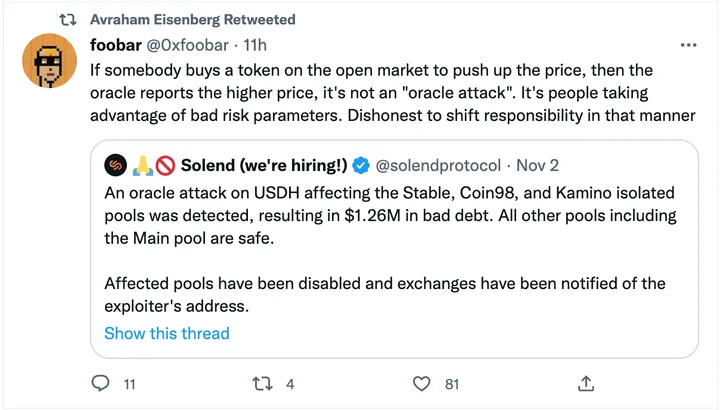
Pyth has 3 main stakeholders: consumers, publishers, and delegators.
-
Consumers: These are users of price feeds, predominantly smart contracts and DeFi protocols. In Pyth v1 on Solana, protocols receive price feeds for free. For protocols outside Solana, they pay small “on-demand” fees to retrieve prices from Pythnet (v2) through Wormhole. Consumers will be able to pay insurance fees once the PYTH token is live to hedge against oracle inaccuracies.
-
Publishers: Publish prices. They receive PYTH token rewards and 20% of data fees (subject to change). They will need to stake PYTH tokens for products they price, and their stake will be subject to slashing if they produce an error.
-
Delegators: Holders of PYTH tokens. They stake on price feeds to determine publishers’ weights and earn insurance fees from consumers. They can be slashed if the feed they stake on produces an error.
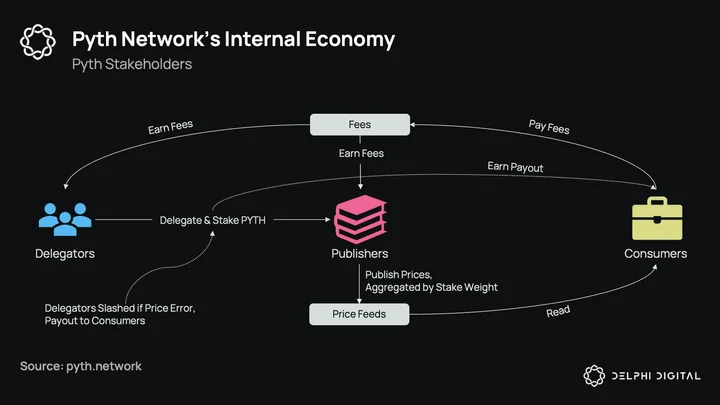
Delegators have an important role to play in determining the aggregate prices Pyth reports. It is their job to weigh which specific publishers should have more/less influence on a feed, and in return earn 80% of the fees consumers pay. Different markets will have varying levels of risk and thus fee income/yield, and it is up to delegators to decide which markets to stake on. For example, a feed like MINA/USD may offer a 5% yield for delegators vs. 1% for BTC/USD, reflecting the failure risk in each feed. Over time, these yields should become more efficient at pricing true failure risk. As for the process of proving a faulty oracle price, that will be done by leveraging HUMAN protocol. We’re not going to go in-depth here (complete details in section 3.1 of the whitepaper), but the gist of it is that the on-chain oracle price published will be compared to off-chain “reference exchanges.” And if the published price disagrees with the reference price (outside of a +/- 3 CI band), then the claim is successful. This process works in two steps. In the first step, a file is claimed. While anyone can file a claim, they must bond PYTH tokens so that spamming on claims can be prevented. In the next step, filed claims get ratified (voted on) by PYTH token holders.
It’s also important to distinguish the slashing risk between delegators and publishers. In the case of a failure, all delegators that stake on that specific feed will be slashed, no matter which publisher was responsible for the bad price, even if they didn’t stake on them. For publishers, they will only be slashed if they themselves are responsible for the error. Delegators will need to balance various factors when staking — for instance, overweighting high-reputation publishers while also making sure no-one publisher has too great an influence, preventing a small number of publisher failures to cause a failure in the aggregate.
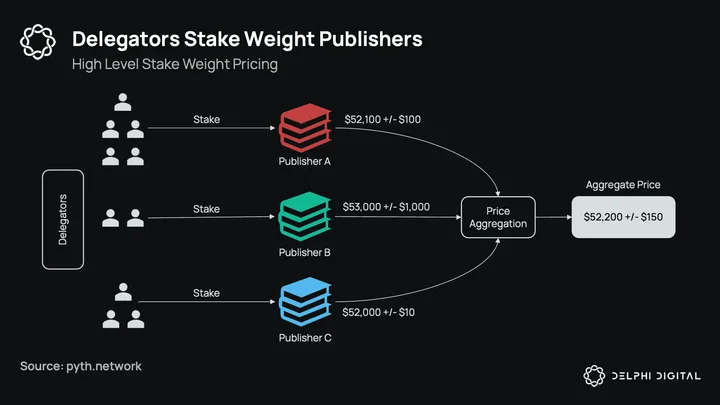
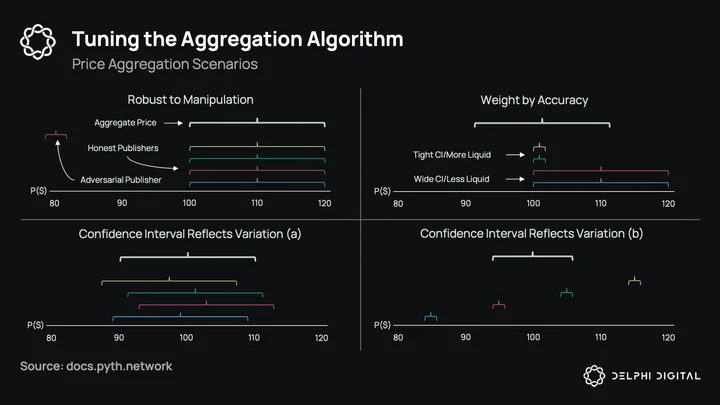
As mentioned, this stake weighting will not be live until after the PYTH token launches. As it stands currently, every publisher is equal-weighted. In addition to the coming stake weighting, Pyth has also overhauled the aggregation algorithm to be more resilient to outliers. The algorithm gives each publisher 3 votes: one at their median, one at the low end of their interval, and one at the high end. These votes are then aggregated and the median of all the votes is the aggregate price, with the 25th – 75th percentile around the aggregate confidence interval. The benefits of this method are:
-
Robust to manipulation: Adversarial publishers (either intentional or accidental) who publish prices outside honest ones will be ignored.
-
Weight by accuracy: Publishers with tighter ranges (i.e. more liquid exchanges) will have an outsized influence on median aggregate price. An exchange that publishes a price of $101 +/- $1 will have more influence on the aggregate price than one that publishes $110 +/- $10.
-
Reflects variation: No assets trade at the exact same price on different venues across the world, and the price published should reflect that.
For a deeper dive (i.e. more math) on the algorithm, you can read here. Once stake weights are live, prices will combine all of these factors to determine price, and publishers will be rewarded on not only their stake weight, but their predictive power and honesty in reported confidence intervals as well.
Evaluating Publishers: Pyth in Practice
Pyth publishers are scored and rewarded according to 3 factors:
-
Stake weight (s): The delegated stake to the publisher, between 0 and 1.
-
Quality score (q): How well a publisher predicts price, between -1 and 1.
-
Calibration (c): A measure of how true a publisher’s reported confidence interval is, between 0 and 1.
At the end of each epoch, rewards are distributed to publishers using a simple formula of s*q*c, and publishers with negative scores are slashed. The fundamental difference here vs. other oracles is that Pyth rewards publishers for sharing new material price information, not simply agreeing with others. The chart below shows two different publishers, one which tracks the aggregate well and another that doesn’t. While tight tracking is obviously preferable, it’s important that this publisher is not just “free-riding” and publishing prices from prior slots (~500ms). This is where the quality score comes in.
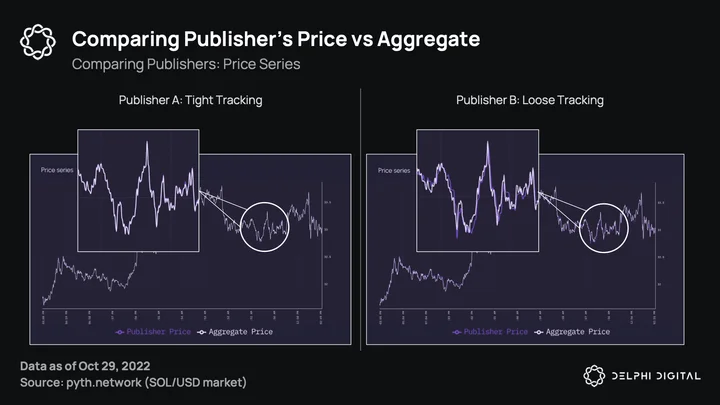
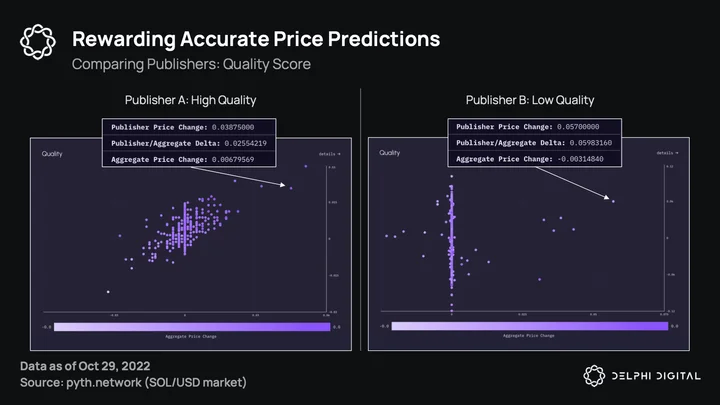
The quality score is an unbiased view of a publisher’s predictive power. A quality score of 1 would indicate perfect price predictions, a score of 0 random predictions, and a negative score (which is unlikely) would be worse than random (i.e. malicious). This is the incentive for market makers and trading firms to share their info. Higher quality predictions will lead to a higher quality score and thus more rewards vs. other publishers, and at the same time prevents bad actors from being rewarded. It also prevents publishers from just agreeing on a price, which would lead to the issue of not being able to differentiate between bad and good publishers, as they would be more likely to just report what others do instead of prices from their own venues. Solana slots are <1s, so any free-riding publisher could just publish what was in the prior slot and track the aggregate without providing any useful information.
The chart below depicts two publishers, one with high predictive power (left) and one with low/random power (right). A high quality score is represented by a smooth color gradient from bottom left to top right.
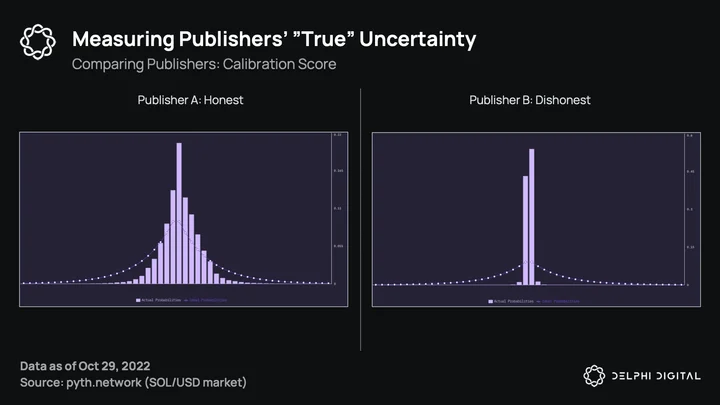
Lastly, publishers are measured on their “true” uncertainty regarding the confidence intervals they publish. Pyth wants high-quality publishers to report tight confidence intervals, but at the same time does not want to overweight tight intervals that are not actually true. This is where the calibration score comes into play, a countermeasure to prevent publishers from reporting falsely tight confidence intervals to achieve a higher quality score. A perfect publisher would achieve a uniform histogram, with the empirical distribution of these differences tracking the theoretical (more like the left of the chart vs. the right).
The Pyth design is a unique and innovative model, differing substantially from other oracles with their introduction of market makers and trading firms, confidence intervals, stake weighting, publisher scores, and aggregation algorithm. Once the token and staking go live, we’ll get to see the entire model in action. Now that we understand how Pyth works, let’s look at some metrics.
Pyth on Solana: Digging Into the Data
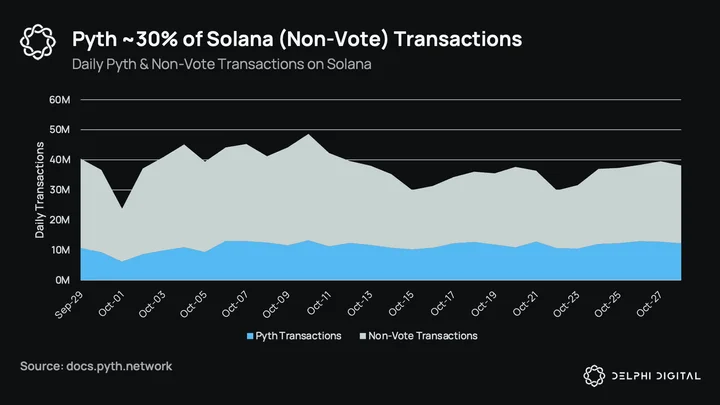
The first thing that should stand out is that Pyth accounts for a lot of Solana’s transactions. After stripping out consensus votes, Pyth is responsible for ~30% of Solana’s transactions. Being on a low-latency chain with fixed transaction costs is what makes Pyth’s frequent updates work. Publishers are updating prices on-chain in every Solana slot (~600ms), something that would be too cost prohibitive and infeasible in other ecosystems.
Even with nearly 10M transactions/day, it’s not too expensive to be a Pyth publisher. If we look at the publisher with the most price feeds (note that publishers are anonymized), they paid ~$7.6k over the past month to update 80 feeds. For now, publishers do not make any revenue as insurance/staking is not live, but they will earn PYTH tokens, data fees, and are (probably) going to receive a token allocation at launch. Also, Pythnet (Pyth’s solution for non-Solana chains) has on-demand “pull” price updates vs. Solana prices being “pushed” on-chain every slot. This will be discussed in a bit, but the on-demand prices from Pythnet will generate additional fees when pulled on-chain.
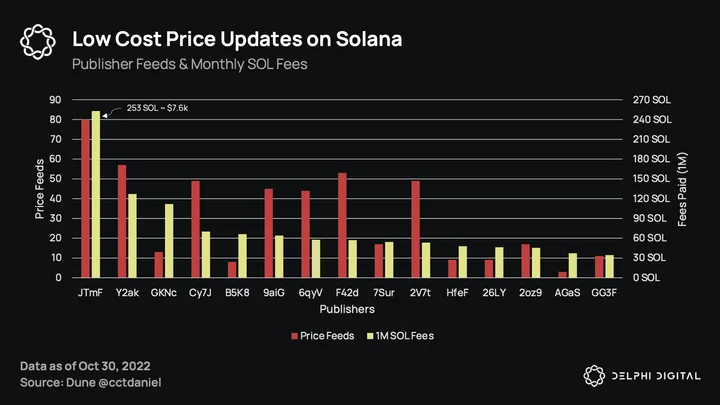
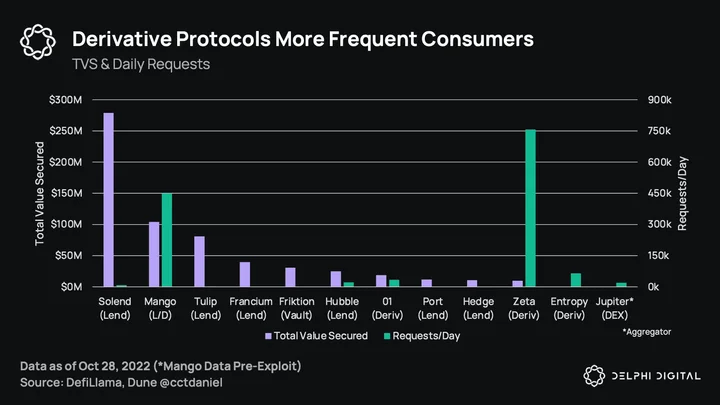
The next thing to highlight is how Pyth is used. While borrow/lend protocols usually have the most value secured (Aave and Compound for Chainlink, Solend for Pyth), they do not request the most price updates. This instead comes from derivatives protocols who need to take advantage of the low-latency prices, vs. a borrow/lend protocol that does not need to update every slot. Pyth has enabled some unique products with their oracles:
-
Mango Markets: A derivatives exchange that uses Pyth for its borrow/lend book and to price their perp market’s funding rate. Mango was one of the first protocols to integrate Pyth’s confidence intervals for their borrow/lend book. Note that the recent unfortunate market manipulation on Mango was unrelated to Pyth.
-
Zeta: Touched on earlier, but a derivatives exchange that uses Pyth’s confidence intervals to prevent manipulation around settlement and to price their futures and options. Pyth is also utilized for their new product FLEX, a permissionless and customizable options protocol.
-
01: Another (surprise) derivatives exchange offering both standard perps and power perpetuals, a product similar to Opyn’s Squeeth. These are like regular perpetuals but raised to a power, offering option-like exposure. They use Pyth for their funding rates.
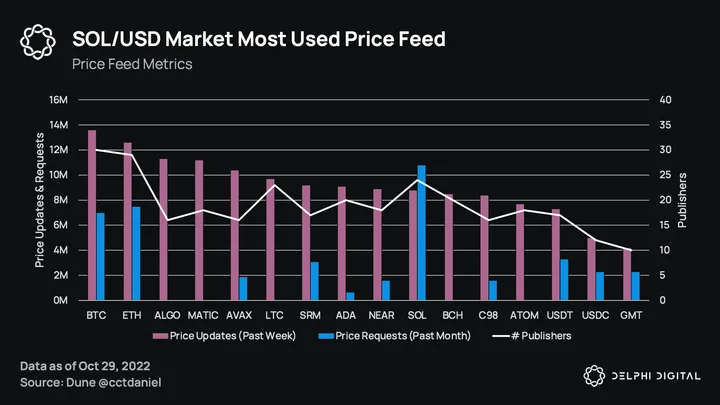
Lastly, we can take a look at which prices have been both published and requested on-chain. This is probably more useful for publishers themselves, to know which feeds are perhaps not worth pricing (ALGO, MATIC, LTC, BCH) and potentially under-covered ones like GMT. It should be no surprise that SOL is the most requested price feed, being on Solana after all. All major assets now have >15 publishers.
While Pyth’s start on Solana got off to a bit of a rocky start, they’ve seen significant performance improvements over the past year and now cover nearly the entire ecosystem (90%+ of Solana’s TVS). But Pyth has aspirations outside of Solana, and this is why they launched Pythnet in August.
Expanding Outside Solana and the PYTH Token
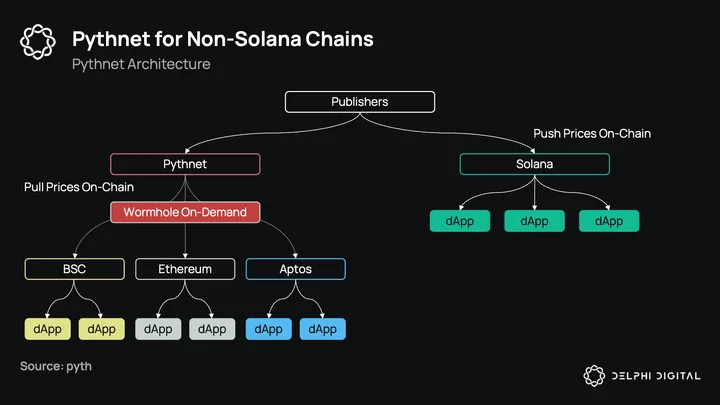
Pythnet is a fork of Solana’s codebase, a separate chain just for Pyth publishers to submit prices. On Oct. 4th they integrated BSC, Aptos on the 19th, and Ethereum and Optimism on Nov. 1st. While Pythnet works like Pyth on Solana for publishers, it’s a different process for consumers. This is because price updates are not pushed on-chain like they are on Solana, instead relying on Wormhole to relay cross-chain messages. The main differences here vs. on Solana are:
-
Pull vs. push model: Prices are “pulled” from Pythnet and updated on-chain when an application requests them, vs. “pushed” automatically on Solana.
-
Increased latency: Latency from CEX price to on-chain is ~3s. 1s of this is from CEX to Pythnet, and 2s from Pythnet to price service (introduced by Wormhole messages).
-
Fees for price updates: Solana protocols can use Pyth for free, while non-Solana protocols need to pay to pull them on-chain from Pythnet. They start cheap at the smallest denomination on-chain (e.g. 1 wei), but can be adjusted by governance later. For a live example, you can watch Pyth’s fee collector on Aurora.
-
Gas efficiency: Gas fees are only paid when consumers actually need prices. If we think back to the price feed chart from the previous section, a lot of gas is wasted on price feeds like LTC and BCH that no one uses.
-
Reliability: Pythnet is its own standalone chain. So if the Solana network goes down, Pythnet still operates.
While the latency is not ideal when compared to the sub-second Solana version, there are mitigations that can be put in place like:
-
Asynchronously settling orders to mitigate any potential front-running. User sends market order → some threshold delay passes (e.g. 2 seconds) → protocol requests most recent Pyth price off-chain → price is pulled on-chain and transaction is executed.
-
Staleness thresholds (not accepting price updates longer than a specific timeframe).
-
Tie a price update request to users’ transactions, only executing a transaction if it uses the latest price.
Also, note that many other oracles who push prices on-chain do not update prices every block due to gas inefficiency. The Pythnet solution allows a real-time off-chain stream that can then be pulled on-chain whenever required. Like anything, we will learn more once it has been used in practice on various chains and there is more data to work with.
Pyth has started to make strides outside of Solana with Ethereum protocols like Euler, Ribbon, and more recently as the oracle provider for Synthetix v2’s perps product with the passing of SIP-285. Chainlink has a long-standing relationship with Synthetix, so this is an important integration for Pyth, especially as Chainlink just announced their new low-latency oracle which should be ready early next year. This integration will arguably be the most important non-Solana one to monitor to see if Synthetix sticks with Pyth when the Chainlink solution is live.
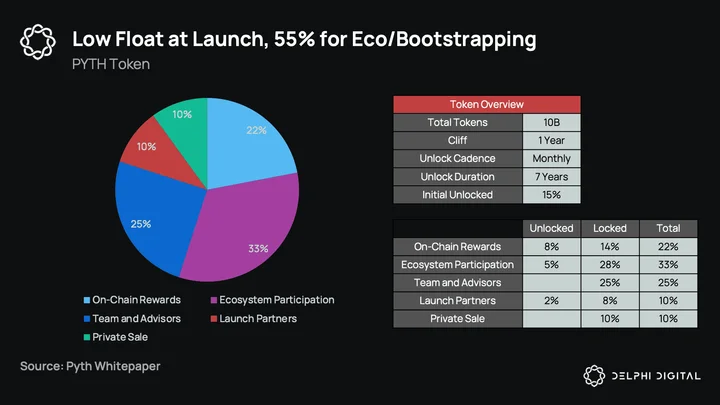
As for the token, while we know a large part is locked for the team and investors, we don’t really know where the initial circulating supply will come from. It’s likely that publishers will get an allocation, and perhaps protocols and (maybe) users of these protocols as well. The unlock duration is quite long, with a 7-year vesting schedule, so there will be a consistent unlock as time goes on. This has the potential to be a low-circulating/high-FDV token, as initial liquidity is likely to be low, especially considering publishers will need to stake tokens (effectively rendering them off the open market). We should learn more about the initial distribution plans soon, and they are important as with the stake-weighting a well-distributed token is vital.
Can Pyth Find Success Outside Solana?
Pyth comes to the oracle sector with a unique angle. This is not a cheap fork or a copy of another model, but a legitimately novel and bold one. They had some growing pains but have been operating much more effectively since. While they cover nearly the entire Solana ecosystem, it remains to be seen how successful they will be outside of it and whether they can make serious inroads with Pythnet. The Synthetix integration will be a good first test, and one that Pyth needs to execute on.