Report Summary
Summary
The report presents zkVerify as a dedicated universal proof verification layer, designed to handle the exploding global demand for zero-knowledge proofs (ZKPs) — a cryptographic method that verifies information without revealing it.
ZKPs are transitioning from niche cryptography to essential blockchain infrastructure. Ethereum and other chains face bottlenecks because verifying proofs is still too slow, expensive, and fragmented. zkVerify aims to solve this by offering a neutral, scalable, low-cost verification platform compatible with any proof system and any blockchain.
1. The Rise of ZK Proof Demand
-
ZKPs are now core to rollups, identity systems, DeFi, oracles, and AI verification.
-
Proof verification demand is exploding — every transaction, ID check, or machine learning inference could soon generate a proof.
-
zkVerify’s network already verified 9 million+ proofs (2.5M on mainnet, 6.5M testnet) and expects 250M+ annually.
-
As AI and identity systems grow, proof demand could reach billions or even trillions per year.
2. zkVerify’s Role
-
Acts as a modular L1 verification layer, able to connect any proof, from any system, to any chain.
-
Designed to eliminate Ethereum’s technical limits (like missing precompiles for ZK systems).
-
Supports multiple proof formats: Groth16, UltraPlonk, Fflonk, Risc0, SP1, Ultrahonk, etc.
-
Developers can submit proofs directly or use zkVerify’s SDK and APIs for easy integration.
-
Cuts gas cost of verification by up to 90% compared to on-chain Ethereum verification.
3. The VFY Token
-
VFY is zkVerify’s native token — used for gas, staking, and governance.
-
Each proof submission pays a fee in VFY; part of that fee may be burned, creating deflationary pressure.
-
As proof volume grows, more VFY gets burned and staked — reducing supply while increasing demand.
-
1 billion total supply; 2.5% annual inflation for validator rewards, offset by burns as traffic increases.
-
Essentially, higher proof traffic = stronger token economics.
4. Partnerships & Use Cases
a. OpenDID (Digital Identity)
-
Enables governments and enterprises to issue and verify privacy-preserving digital IDs using zkVerify.
-
zkVerify confirms ID proofs without storing personal data.
-
Potential rollout in Singapore, Hong Kong, and Vietnam — each capable of generating millions of recurring proofs.
b. Phala × zkVerify (Trusted Compute)
-
Integrates zkVerify with Trusted Execution Environments (TEEs) for verifiable confidential computing.
-
Cuts verification gas by ~90% and proving costs by ~20%.
-
Allows AI or game computations to be verified directly without extra wrapping layers.
c. Singularity (Private DeFi / Dark Pools)
-
Uses zkVerify to verify private institutional trades while keeping orders confidential.
-
Every trade or match generates a proof, verified cheaply by zkVerify.
-
Represents a high-volume, high-frequency source of proof traffic.
d. ShadowML (Verifiable AI Compute)
-
Each ML model inference generates a ZK proof to confirm correct execution without exposing data.
-
Opens the door to verifiable AI, where every prediction or output is provably correct and private.
5. Technical Innovations
-
Relayer product: lets Web2 developers integrate proof verification via API without blockchain wallets.
-
Photo authenticity proofs: links mobile-captured images to secure enclave attestations — proving photos are real and unaltered (useful for media, legal, insurance, etc.).
-
Gaming integrations (zkSlots, zkBlackjack, etc.) already generated 400K+ proof transactions, showcasing scalability for real-time verification workloads.
6. Conclusion
zkVerify positions itself as the neutral infrastructure layer powering the next generation of verifiable computation, identity, and AI.
Its modular design, wide proof compatibility, and efficient cost structure could make it the “AWS of verification” in a world where every interaction produces a proof.The VFY token links this usage to value accrual through staking and potential burn mechanisms, creating a usage-driven economic loop.
Key Takeaways
-
ZK proof demand is exploding — billions of verifiable events (AI, identity, finance) will need efficient verification.
-
Ethereum’s verification layer is limited; zkVerify solves this with a universal, scalable alternative.
-
VFY token economics benefit from rising proof volume through burns and staking incentives.
-
Partnerships (OpenDID, Phala, Singularity, ShadowML) already secure massive proof inflows across major sectors.
-
zkVerify’s relayer & SDK make it easy for Web2 and enterprises to integrate cryptographic verification without blockchain complexity.
-
Photo authenticity & AI verification use cases expand zkVerify beyond crypto — into media, legal, and identity applications.
-
zkVerify is becoming the universal verification layer for the modular, ZK-powered internet of the future.
-
Introduction
Zero-knowledge proofs (ZKPs) have moved from theoretical constructs to production-ready infrastructure in the last few years. The recent launch of zkVerify mainnet and their native token VFY is a testament to that.
If you’ve been in the space long enough, you’ll recall how ZKPs have had sluggish adoption and difficulties when it came to practical integrations. Ethereum experimented with zk-SNARK precompiles as far back as 2017, but the costs and limitations meant proofs were rarely used outside specialized cases like Tornado Cash. It wasn’t until the modular blockchain thesis matured, and zk-rollups demonstrated production-grade deployments. But even then, ZKP verifications have been fragmented with different standards and different verifiers, all siloed from one another.
Today, we stand at the cusp of ZKPs moving from specialized cryptography to ubiquitous infrastructure. zkVerify is making that possible as a modular verification layer that can connect any proof, on any system, with any chain.
Since our last coverage on zkVerify back in August, the total transactional volume of proofs flowing into the network has eclipsed 9M verified proofs (~6.5M on testnet and ~2.5M on mainnet). zkVerify also has an estimated proof pipeline of ~250M+ proofs projected over the coming year. These estimates are variable, but on a 12-month forward looking projection it considers overall proof volumes coming from each partnership.
If this demand continues to accelerate, there is a chance that proof verification could reach multi-billions, or even trillions, in the future. That’s exactly what we’ll cover in this memo: the growth trajectory of ZKPs, the potential outlook on the proof market, and how zkVerify has strategically positioned itself to become the universal proof layer.
Measuring the TAM of ZKPs – An Explosion in Proof Demand
The proving market is entering an inflection point. For most of crypto’s history, proof generation and verification were bottlenecks. They were too costly, too slow, and too specialized to matter beyond niche applications. This simply isn’t the case anymore.
Demand for proof verification is coming from every potential use case imaginable. Each zk-rollup batch submitted to Ethereum is a proof. Every decentralized identity credential is a proof. Bridges, coprocessors, oracles, and even onchain gaming all rely on proof verification to some extent. Even Vitalik’s vision for Ethereum has been the ZK endgame for quite some time.
Now, what happens in a world suddenly proliferating with opaque AI models and black box inference? Or models that must operate on highly sensitive data? Think medical records, identity credentials, or proprietary datasets. Secure enclave environments like TEEs are already enabling this kind of confidential inference, but they still depend on cryptographic proof layers to make their results publicly auditable.
The fact is that we are moving into a future where every computation, interaction, and identity claim will need to be verifiable. How do you know that an inference was performed correctly, or that the model weights haven’t been tampered with? zkML provides the answer by embedding proofs into the inference process itself. Every model query could eventually be accompanied by a proof that the computation followed the declared rules and datasets. This creates an entirely new market for proofs.
Other primitives like zkTLS extend verifiability beyond computation to the transport and authentication layers. zkTLS allows users to prove that a connection or session followed a valid TLS handshake. This means web interactions themselves can become trust-minimized and verifiable. As traditional systems expose verifiable endpoints and blockchains standardize proof ingestion, our digital lives start to become cryptographically composable. The idea is that proofs effectively become a common trust layer between legacy systems and blockchain networks.
Once proofs become as ubiquitous as digital signatures, extrapolating future projections of proofs into the trillions no longer seems like a far-fetched claim. And this trajectory only accelerates as proof generation moves to the edges, such as the case with billions of mobile devices.
We’ll cover it deeper later in the report, but zkVerify has already demonstrated proof-of-concept integrations where photos and videos captured on mobile are accompanied by secure enclave attestations, and verified directly through zkVerify. Combining this with device-linked digital IDs unlocks new forms of authenticity. As mobile devices become additional points of proof generation, the proof economy expands into everyday human interaction.
VFY Token – Capturing The TAM
So where does the VFY token sit in all of this?
On the surface level, VFY plays the role of the native governance, staking, and gas token of the zkVerify network – similar to any L1. However, on a more nuanced level, the token model is designed to capture value directly from the growing demand for proofs through a combination of fee sinks and deflationary pressure.
Before I begin, I’ll caveat that the token burn mechanism is still currently conceptual, but an integration plan has been mentioned nonetheless.
At some point, the $VFY supply stops growing.
As @john_camardo explains, once burned fees outweigh block rewards, supply begins to shrink.
That makes every token a larger share of the network and increases the governance power of each holder ⤵️ pic.twitter.com/GxEOqGVyn0
— zk V e r i f y (@ZKVProtocol) September 27, 2025
The main component here is the token burn mechanism. Each time a proof is submitted to zkVerify for verification, a small portion of the fee paid is intended to be collected in VFY and effectively burned. This means as proof throughput grows, so too does the VFY burn rate. Proof verification fees become the network’s monetary policy instrument, essentially a mechanism that turns exponential usage into a supply contraction.
This mechanism sits within a broader token flywheel that reinforces demand from multiple fronts. Every actor in the zkVerify ecosystem interacts with VFY in some capacity. Provers and users acquire it to pay verification fees, validators stake it to secure the network and earn rewards, and the protocol recycles a portion of revenues into staking yields and ecosystem incentives. This creates a closed economic loop:
Growing proof volume increases fee revenue, which tightens token supply through burns while simultaneously raising the incentive for validators to stake more VFY to handle higher workloads.
VFY has a fixed total supply of one billion tokens, with an annual inflation rate of around 2.5% earmarked for validator and staking rewards. The inflation acts as a baseline security subsidy, but is counterbalanced by the burn mechanism tied to verification volume. If proof traffic scales as projected, burn pressure can offset or exceed issuance, effectively pushing the token toward a deflationary equilibrium. The long-term supply curve, therefore, depends less on arbitrary emissions and more on organic network usage.
*In the following diagram we assume a hypothetical 20% burn rate on fees collected.
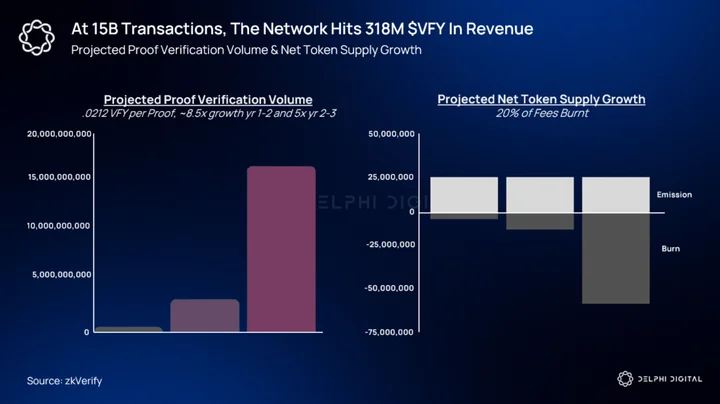
From a value accrual standpoint, the metrics worth considering are:
- the net burn rate (tokens burned minus newly issued)
- the proportion of supply locked in staking
- the growth in verification fees per proof
- the overall proof throughput of the network
A rising burn rate and a high staking ratio compress liquid supply, while growing throughput compounds token demand.
The thesis is straightforward. If proof generation becomes as common as digital signatures or API calls, then the layer that verifies those proofs will effectively control the proof economy. zkVerify is strategically positioning itself to play that role. The more proofs are produced, the stronger the structural demand for VFY.
As mentioned, much of this is currently theoretical at the time of writing. zkVerify has emphasized that there will be no token burn right out the gate, but plans to implement it eventually exist. It’s also worth considering that the success of the token flywheel does hinge on the sustained volume of the proof market, as well as zkVerify being the market leader.
So far, that seems to be the case, as they have already blown through competitors like Aligned Layer. For context, Aligned Layer has ~32k verified proofs while being in production for much of the year and launching mainnet well ahead of zkVerify.
Capabilities of Proof Verification
In our previous zkVerify reports, we covered the different proof types, their current implementations, and the cost reduction element in extensive detail. Here, we will touch on the current constraints of those proof types that zkVerify is openly solving. If we anticipate proofs to project into the multi-billions/ potentially trillions annually, performance and scalability will likely determine where these proof volumes ultimately flow.
To set some context, there are a few constraints we’ll be focusing on:
- Ethereum’s lack of necessary precompiles
- The fact that STARK proofs (like Risc Zero/SP1) consume too much space
- The issue with STARK to SNARK compression vs. direct verification
A practical assessment of any verification layer must consider the execution environment it hopes to serve. This has been the longstanding constraint with Ethereum’s lack of necessary precompiles. Until recently, the EVM exposed only a small set of pairing and ECC precompiles (EIP-196 / EIP-197 for BN-254), which made verifying higher-security SNARK curves or more exotic primitives awkward and gas-expensive.
Proposals such as EIP-2537 (BLS12-381 precompiles) have been discussed as a potential solution. But historically, the lack of broad precompiles constrained what proofs were feasible to verify directly on Ethereum. This effectively pushed projects toward either expensive onchain verification or complex off-chain settlement patterns.
Part of the reason some proving stacks prefer off-chain aggregation or specialized verification layers is a direct consequence of proof-type economics. STARK-based proofs (and many zkVM receipts built from STARK primitives) are typically larger than succinct SNARK proofs. That size difference matters operationally. Larger proofs generally mean higher bandwidth, higher storage, and greater onchain cost if the target chain charges for calldata or storage.
For example, Risc Zero’s design is a STARK-based zkVM that produces receipts intended to be verifiable off-chain or compressed before final settlement. Similarly, SP1 (Succinct’s zkVM) explicitly exposes proof type tradeoffs (core, compressed, PLONK) because raw STARK-style outputs require additional engineering to be convenient for onchain settlement at scale. The TLDR is that STARKs trade transparency and post-quantum properties for larger byte footprints, and that trade drives architectural choices for verification.
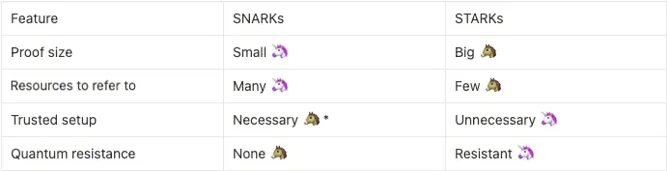
Source: Throne of ZK: SNARK vs STARK
Those architectural choices lead directly to the direct verification vs. conversion/compression tradeoff.
Direct verification is self-explanatory. The destination chain or verifier accepts the proof format as-is (verifying a STARK receipt natively). Conversion or compression is transforming a large STARK proof into a smaller SNARK, so onchain verification becomes O(1) and independent of the original program size.
O(1) verification = the proof verifies in constant time and cost, independent of computation size.
Several projects have published explicit pipelines for this approach. Aggregating many STARK witnesses into fewer artifacts, then applying a recursive SNARK step (or a STARK to SNARK transformation) so the verifier only needs to check a tiny SNARK. This reduces onchain work at the cost of additional off-chain proving complexity.
zkVerify’s approach is to avoid forcing users into one side of that tradeoff by supporting both paths where practical. If you’ve been keeping up with our coverage, you’ll know that zkVerify supports a broad array of proof systems (Groth16, Fflonk, UltraPlonk/UltraHonk, Risc0, SP1, Plonky2), with plans to support every proof type, prioritizing those with the most demand and use cases.
zkVerify also provides native verifier implementations and SDKs for several of these formats. This means projects can submit proofs in their native format or choose to compress/aggregate before settlement, depending on their cost/latency profile.
Ultrahonk
zkVerify is constantly adding verifiers to attract specialized projects and proof types. One of those is Ultrahonk, a middle path between large STARK-based proofs and more succinct SNARKs. Developed using the Noir compiler and Barretenberg backend, Ultrahonk proofs employ Keccak256 for transcript hashing and support up to 32 public inputs. The appeal of Ultrahonk is its capacity to verify certain computations directly (i.e. without needing a STARK proof to be compressed into a SNARK), which reduces both latency and overhead in scenarios where the computation fits within Ultrahonk’s supported limits.
Supporting Ultrahonk means more developers can avoid the STARK to SNARK compression where it’s overkill and reduce overall system complexity without all the arduous workarounds. Another reason why Ultrahonk is special is because Ethereum and other EVMs without special precompiles cannot verify these specific proofs.
Below is a comparison of Ultrahonk against the existing proof systems:
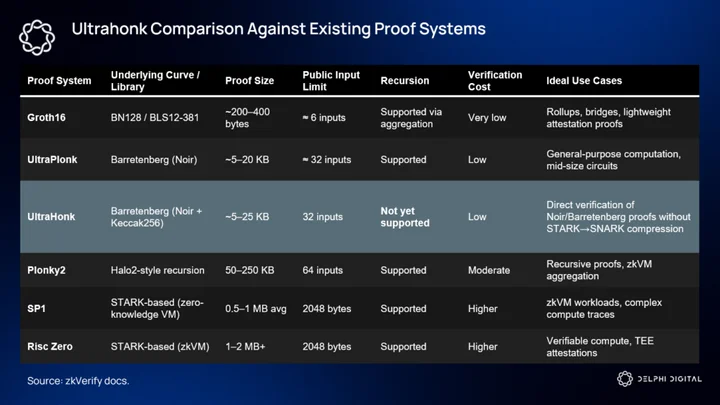
But Ultrahonk is not a silver bullet. Its lack of recursion means that workflows requiring proofs of proofs or deeply nested verification still need other mechanisms. This would require either direct verification using other proof systems (Risc Zero, SP1) or converting/aggregating proofs. Also, the public-input limit of 32 imposes constraints on how large the public witness can be, limiting some use cases.
However, the main takeaway is that Ultrahonk proofs cannot be verified on most networks directly because those networks lack the required precompiles (native verifier opcodes). zkVerify essentially commoditizes access to proof systems that would otherwise be unusable on major chains like Ethereum. By abstracting away the need for protocol-level integrations, zkVerify enables deployment of apps that specifically utilize Ultrahonk proofs. These are generally latency-sensitive use cases such as gaming, verifiable off-chain computations, or anything that requires direct verification without heavy compression layers.
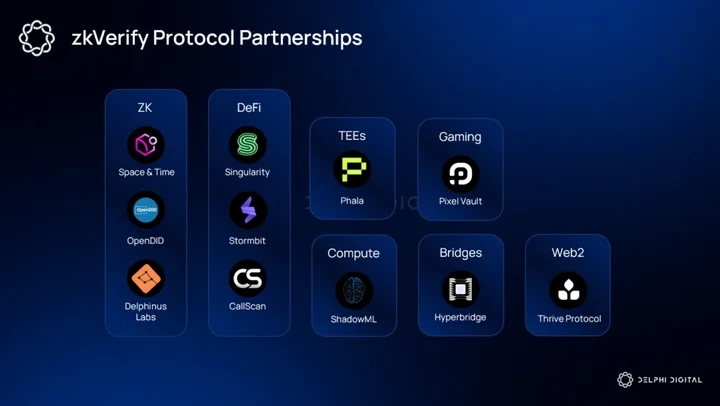
Partnership Developments
zkVerify has taken a proactive B2B approach, partnering with multiple high-volume proof submitters and verification protocols. While the engineering team has been pulling proofs from other networks, the business team has been integrating with protocols spanning across multiple application verticals, including identity, private DeFi, verifiable compute, and even web2 services.
OpenDID & ZK-Identity
One of zkVerify’s key strategic partnerships is with OpenDID, a decentralized identity infrastructure that enables governments and enterprises to issue verifiable credentials using ZKPs. Large-scale identity attestations are a use case that stands to generate some of the highest proof volumes of any vertical in the ecosystem. National-level identity systems can effectively produce millions of credentials, each requiring periodic verification or renewal.
At a technical level, the zk-Identity stack allows government institutions or trusted issuers to create digital IDs using a decentralized identifier (DID) that maps to a verifiable credential schema. When a user presents a credential (for example, to prove they are over 18, or a resident of a given jurisdiction), the system generates a ZKP attesting to the validity of that claim. Instead of the verifier recomputing or storing the credential data, zkVerify checks the proof itself and writes an attestation to the chain. The result is an immutable yet privacy-preserving verification record that can be referenced by any external service.
OpenDID serves as the credential orchestration layer, while zkVerify acts as the independent verifier of proofs that correspond to those credentials. The collaboration effectively disaggregates the identity stack. OpenDID handles who issues credentials, while zkVerify guarantees that the credentials were verified correctly.
For zkVerify, it means access to one of the largest potential sources of recurring proof traffic, as every credential issuance, update, or cross-system verification becomes an onchain proof event.
At the moment, zkVerify plans to bring this to Singapore, Hong Kong, and Vietnam.
Phala × zkVerify – TEE integration
Phala provides a production-ready Trusted Execution Environment (TEE) stack that turns hardware enclaves into a usable developer platform for confidential compute. TEEs produce cryptographic attestation reports proving that code was executed inside an enclave and that outputs were produced by that trusted runtime. Phala layers a developer SDK, a decentralized KMS, and runtime abstractions on top of the raw attestation primitives so teams can run private compute (think AI inference, RNG, game logic, etc.) at scale.

The core integration value between Phala and zkVerify is reducing the trusted surface and cost of turning TEE outputs into publicly verifiable attestations. Historically, teams that wanted onchain settlement of TEE results had two options:
Accept heavy onchain calldata (which is expensive) or wrap enclave attestations inside an additional SNARK step (e.g., Groth16).
zkVerify’s integration with Phala removes that extra wrap in many cases. zkVerify can directly verify SP1 (STARK-style) and Risc Zero receipts produced by Phala’s stack, skipping the Groth16 conversion step entirely. The direct-verify path shortens the pipeline (fewer transforms, less latency), lowers end-to-end cost, and preserves the stronger security/expressivity properties of the original TEE > zkVM output. zkVerify and Phala present this as materially faster and cheaper than earlier approaches, citing ~20% cost savings in proof generation and ~90% lower gas fees compared to verification on Ethereum.
We can visualize a typical technical flow as follows:
A job runs inside a Phala enclave (for example, an RNG shuffle for a provably fair onchain game). The enclave emits an attestation plus a proof artifact (a Risc0 or SP1 receipt) that cryptographically ties the output to the enclave code and input. That receipt is submitted to zkVerify, which performs native verification of the receipt type and publishes an attestation (proof receipt/Merkleized acknowledgment) onchain. Consumers (games, identity services, etc.) then reference zkVerify’s receipt rather than repeating heavy verification themselves.
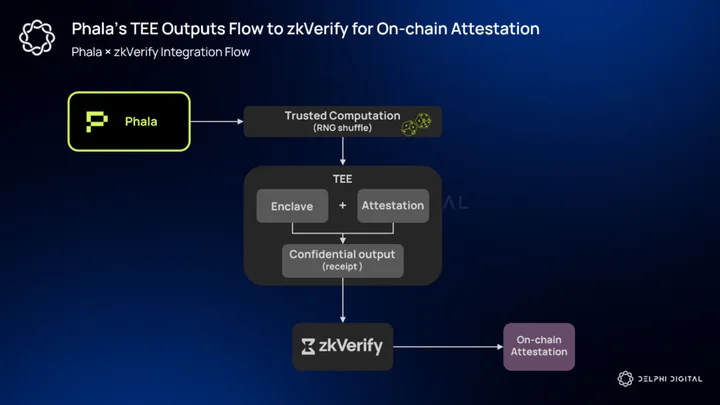
There are also important security and engineering caveats worth noting. TEEs are powerful but not infallible. Hardware attestation schemes have historically had vulnerabilities, and Phala explicitly couples TEEs with cryptographic KMS and operational controls (key rotation, minimized runtime) to mitigate those risks.
Combining TEE attestation with an external ZK verification layer is a defensible design approach. The TEE proves correct enclave execution; the ZK receipt proves the computation or translation layer mapped inputs to outputs correctly; and zkVerify’s published attestation provides the immutable, auditable record.
Singularity – Private DeFi (Dark Pools)
Singularity is building an institutional-grade onchain dark pool that combines ZKPs and other privacy primitives to enable trading without exposing order size, price, or strategy to public mempools and front-running actors. Singularity explicitly positions itself as a compliant, confidential execution layer for institutions, and its roadmap includes pairing ZKP infrastructure with onchain settlement so trades can be executed privately but settled transparently.
From a systems perspective, the integration is relatively straightforward but materially important. A dark-pool flow looks like this in practice:
- Institutional participants submit encrypted or otherwise hidden orders into Singularity’s matching engine.
- The matching engine computes execution and clearing results in a confidential environment.
- Singularity then produces a cryptographic proof attesting that the matching and price/time priority rules were followed correctly without revealing the private inputs.
- That proof (or an aggregated receipt covering many trades) is submitted to zkVerify for independent verification and anchoring.
- zkVerify verifies the proof natively or accepts a compressed/aggregated receipt and writes an attestation to its settlement layer. The external onchain settlement logic references zkVerify’s attestation instead of re-executing or trusting a centralized operator.
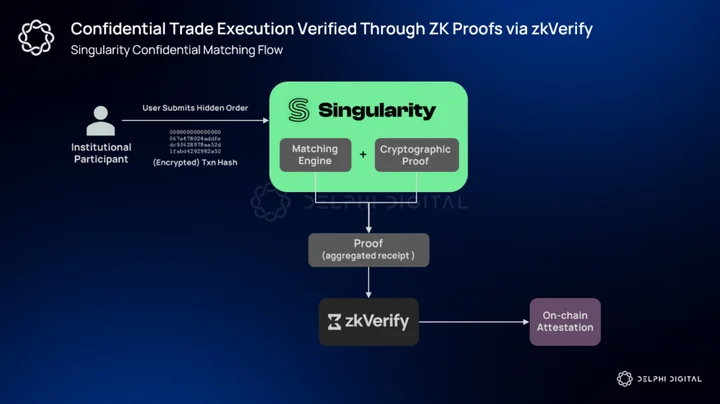
The result is private execution with public verifiability. Institutional guarantees of a dark pool plus the auditability and finality benefits of cryptographic settlement.
Once again, this integration materially benefits zkVerify. Private trading venues generate a very high rate of small proofs. Each order match, partial fill, or clearing event is a verifiable state transition that can produce a proof. Because Singularity targets institutional flow (block trades, algorithmic execution), the expected proof density is high relative to most retail DEX activity.
Passing that traffic through zkVerify concentrates verification at a neutral layer designed for high throughput and low per-proof cost, rather than forcing each participant or settlement chain to perform expensive onchain verification. This effectively turns Singularity from a single customer into a recurring high-volume submitter that feeds into zkVerify.
Dark pools and private DeFi are a huge strategic vertical for driving significant proof inflows. Most transactional volume in crypto is attributed to onchain trading. Now imagine if even a fraction of that volume could flow into zkVerify via dark pool venues like Singularity.
Beyond that, zkVerify has partnered with Stormbit for privacy-preserving lending, Unwallet for stealth addresses, and CallScan for trading verifications within the DeFi domain.
ShadowML – Verifiable Compute
Verifiable compute is the class of applications in which the result of a computation must be proven correct to third parties without revealing sensitive inputs. Examples predominantly include ML model inference (did model N, on input X, produce output Y?) and biometric/personhood attestations. As the integration of AI systems in our daily lives proliferates, the demand to differentiate humans from machines or verify the correctness of a given ML model increases simultaneously.
ShadowML is a decentralized platform for confidential machine learning that now integrates directly with zkVerify. Spun out from one of zkVerify’s hackathons, ShadowML routes proofs from ML predictions to zkVerify for onchain verification. This means every ML prediction is accompanied by a verifiable proof. The proof verifies that the ML prediction was generated by the intended model, using the correct logic, without disclosing any proprietary parameters or private input data.
ShadowML empowers ML providers to monetize their models without exposing:
• Training data
• Proprietary thresholds
• Model logicUsing ZK proofs, predictions are verifiable without revealing sensitive details.
— zk V e r i f y (@ZKVProtocol) October 3, 2025
Model providers can monetize their models through per-inference payments while maintaining total confidentiality over weights and datasets. zkVerify’s low-cost verifier pallets cut onchain verification costs by ~90% compared to general-purpose chains. Conceptually, this fits within the broader thesis of verifiable compute, where workloads like ML inference, identity attestations, and TEE-based computation converge into a single proof economy.
Another, yet hypothetical, large-scale identity network example is a Worldcoin-style integration. Such a system performs millions of identity checks (biometric scans, liveness tests, uniqueness checks). If it wants cryptographic auditability without exposing personally identifiable information (PII), each of those checks can be converted into a verifiable artifact (zk proof, TEE attestation + zk receipt, or zkML inference proof).
How large the proof market can extrapolate to in a world where proving personhood becomes more common is an important consideration. And while no such partnership exists today, the same verification model still applies.
If each ML inference or identity verification produces a verifiable artifact, proof volume scales not linearly but exponentially with AI and identity adoption. From a market perspective, the implications for zkVerify are enormous. AI and verifiable compute could become the largest single source of recurring proof submissions, far outpacing traditional ZK rollups or DeFi attestations.
Technical Developments
zkVerify recently went live with their mainnet and launched the VFY token on September 30, 2025. VFY is currently listed on Binance Alpha, KuCoin, Gate.io, MEXC, Aerodrome, and a long tail of exchanges.
The integration of games has become an effective on-ramp for user acquisition and proof generation. zkSlots, zkBlackjack, and Space Invaders have collectively generated over 400,000 proof transactions and demonstrated the system’s capacity to handle high-frequency, low-value verification workloads.
The relayer product has also seen significant adoption and volume. It exposes simple REST/JavaScript integration so non-blockchain teams can submit proofs without a wallet, and it implements an “optimistic pre-verification” path that checks proofs in under 200ms before final settlement.
This product is explicitly positioned to onboard Web2 developers and enterprises by removing the usual crypto UX friction. The team reports real adoption with ~507 unique API keys issued and 15+ applications already integrated, with the relayer used to feed proof traffic into zkVerify.
Another core technical development that deserves special emphasis is the photo authenticity proof system, which the team prototyped using secure enclave attestation + zk receipts. The idea is to use device-level secure hardware (Apple Secure Enclave – as shown in the post below or equivalent TEEs) to cryptographically bind the act of capturing a photo to a timestamp, device identifier, and a short attestation that the raw pixels originated inside the device.
📸 Proof of secure media 📸
Prove that a photo is actually captured on an iPhone, at a specific timestamp, and was not tampered 😎
Built with @Apple Secure Enclave, @SuccinctLabs SP1, and @ZKVProtocol
Secure key generation & signing 🤝 Efficient ZK proof verification pic.twitter.com/mTqkVhXgLc
— Arman Aurobindo (@aurobindo_arman) September 9, 2025
That enclave attestation (or a derived zkVM receipt) is then submitted to zkVerify for verification. zkVerify publishes a compact receipt or Merkle root onchain, enabling third parties to confirm that an image was genuinely captured on an enrolled device at a claimed time without revealing the image itself.
This is a mobile-native use case with enormous addressable demand, including journalism, legal evidence, insurance claims, age verification (dating apps, etc.), and provenance for media distribution. As deep fakes become more sophisticated, so too does the need for tools that detect them.
There are however, engineering and product caveats to highlight. On the engineering side, enclave attestation schemes vary across vendors (Apple, Android, etc.) and are subject to hardware and firmware lifecycle issues. Integrating many device families requires attestation-translation layers (formatting into a common verification standard) and KMS/key-rotation practices.
On the product side, a provable photo pipeline must anticipate user behaviors that strip or transform metadata (resizing, recompression), so the UX needs to make capture + attestation the canonical “authentic” flow (e.g., an app that captures and attests in one action). Modifying a photo, whether it is through compressing, cropping, or filtering, would effectively break the original attestation hash. If a photo was captured and then altered, it’s no longer verifiably “authentic.”
The system must also include replay protection (nonces and short validity windows) and revocation primitives (time-bounded attestations or onchain revocation roots) so proofs cannot be reused or misrepresented later. Regardless, this development is a step in the right direction, considering the future we are moving towards.
Conclusion
ZK proofs are moving from niche cryptography to ubiquitous infrastructure. Proof volumes are scaling exponentially as rollups, zkML, identity systems, TEEs, and private-DeFi workloads proliferate. Each new verifiable interaction (an ML inference, a biometric check, a dark-pool settlement) multiplies the demand for low-cost, neutral verification. That is the market opportunity: verification is the bottleneck the industry must solve to make ZK practical at a global scale.
zkVerify has built a credible pathway to occupy that bottleneck. Supporting multiple proof types, providing proof-aggregation primitives, and a relayer/API product that lowers integration friction for Web2 and enterprise teams. Strategically, it is executing the neutral-substrate play: accept proofs in their native formats where practical, enable aggregation/recursion where scale demands it, and publish attestations that downstream systems can trust.
Economically, the VFY token has the potential to tie the protocol to that growth. Fees denominated in VFY, the opportunity of a defined burn fraction from collected fees, staking for security, and revenue share mechanics could ultimately create a usage-driven flywheel. Under realistic proof-volume scenarios, modest per-proof fees compound into meaningful protocol revenue and token scarcity.
But zkVerify’s ambitions are greater than “realistic” proof volume scenarios. As we mentioned, they project a ~150M annualized proof run rate, with a potential to exceed ~250M proofs with their current customer pipeline alone (OpenDID being one of the largest sources). And although their thesis of proofs reaching trillions on an annual basis in the future sounds slightly hyperbolic, there’s no denying the extent to which the proof market is rapidly growing. Regardless of the numbers, ZKPs need a neutral verification layer, and zkVerify is currently at the forefront.
0 Comments