The Year Ahead for AI + DePIN 2025
DEC 19, 2024 • 122 Min Read
The Year Ahead for Crypto 2025 – Full Series:
AI+DePIN
DeFi
Gaming
Infrastructure
Markets
The Year Ahead for AI + DePIN
Note: the following report is broken down into two sections: Part I is focused on AI. Part II is focused on DePIN.
The two sections are married in the middle by a section on data, applicable to both. Reading together is encouraged, but given its length, readers should feel free to view this as two separate reports.
PART I: AI
Macro
AI is the defining technology of our age. And as we enter 2025, humanity stands on the precipice of great change. We are witness to nothing less than an evolutionary shift — one from biological to silicon minds. So far, things have gone smoothly. Most remain blissfully unaware of just how different the world will look in a few years time. But for those who live and breathe this space, the change can be jarring and hard to process. We hope this report brings a measure of clarity to what is perhaps the most profound moment in human history.

If 2023 was the year AI broke the Internet, then 2024 was the year AI broke financial markets. From Nvidia becoming the most valuable company on Earth, to OpenAI eclipsing a $157 billion valuation, to Elon Musk raising $6 billion for the one-year-old xAI. Markets have been captivated by the promise of artificial technology to a degree unseen in a generation.
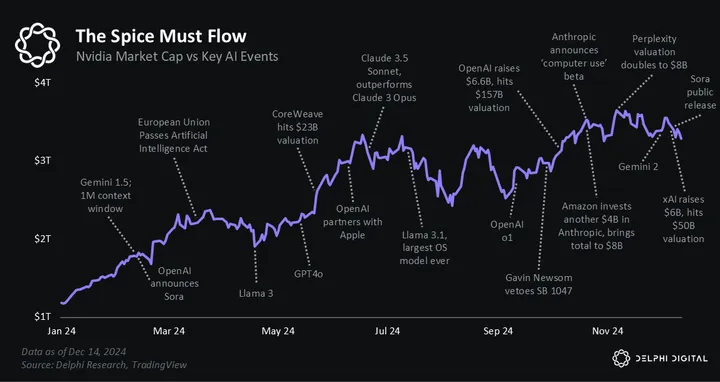
All the speculation has created immense wealth but also drawn warnings of a mania. The critics claim AI is hot air; some even call it the next Dot Com bubble. But we see things differently. We believe AI has two fundamental ingredients that distinguish it from previous boom and bust cycles:
- capex
- generality
AI is unique from recent computing waves like mobile and social media as it requires a massive amount of physical infrastructure. To ‘make AI’ you first need a lot of electricity, chips, and interconnects before you can even start. This requires building physical things in the real world. It’s a vastly different paradigm than mobile, where devs built Flappy Bird apps and social media, where the only real ‘building’ was follower counts. Society has grown used to operating in the world of bits, but AI is making atoms great again.
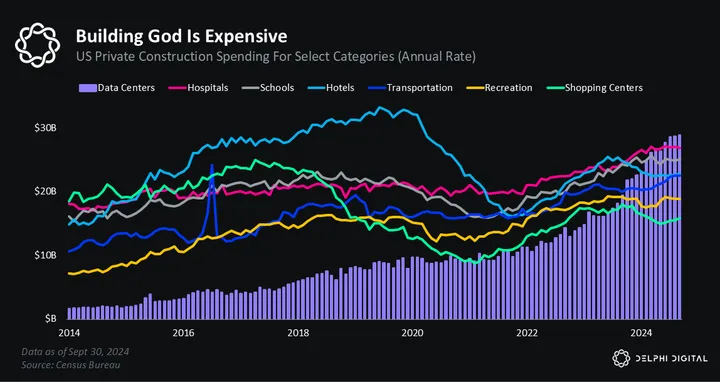
The upshot for markets is that AI will drive wealth creation across a much broader swath of society than in previous technology cycles. With social media, only the engineers in San Francisco and influencers in New York benefitted. But with AI, the local electrician benefits, the concrete guy benefits, and the mom-and-pop HVAC shop benefits. AI’s insatiable hunger for physical infra is driving a CAPEX boom across the country, and the spending looks set to accelerate from here.
some highlights
> wants to build 5GW data center
> 5GW = the entire city of LA
> wants to build 5-7 of them
> that’s 5-7 new LAs to the grid
> 1) whathttps://t.co/vZKpbRkgvS— mrink0 (@mrink0) September 27, 2024
The second reason why AI will be singular in its impact comes down to the very nature of artificial intelligence. At a high level, there are two kinds of technologies. The first is an iterative update to the world — like moving from the iPhone 15 to iPhone 16. These ‘updates’ often introduce some cool new tech but rarely change anything in a meaningful way.
Steve wouldn’t have shipped that ad. It would have pained him too much to watch.
— Paul Graham (@paulg) May 8, 2024
The second set of technologies are the ones that deliver dramatic cost declines, impact many industries and geographies, and serve as a platform for future innovation. Economic historians refer to these as General Purpose Technologies (GPTs).
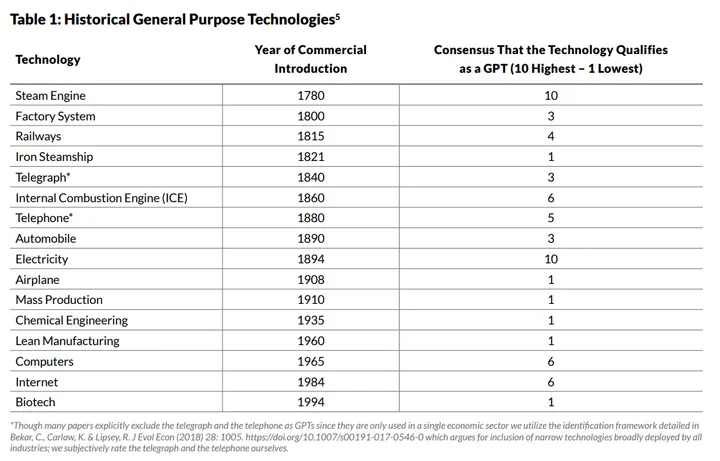
Electricity is considered a GPT since it provided a discontinuous reduction in the cost to generate, transmit, and deploy power. Adoption was widespread across sectors, with applications at both the business and the consumer levels that inspired many other innovations to be built on top of them. Similarly, artificial intelligence is accelerating computational capabilities far more rapidly than expected, with ramifications for every industry, including multi-trillion-dollar innovations beyond what we can imagine now.
In plain English — AI will create orders of magnitude more wealth than past technology waves due to its ability to impact everything, everywhere, all at once. It will transform computing, medicine, manufacturing, agriculture, science, and the rest of the world with it. The economic ripple effects of such a profound change are hard to fathom and impossible to predict. But we can safely say we are not living through another pets.com fractal.
productivity growth is 3.4%
“we had averaged just 1.1 percent in the decade prior to the pandemic” https://t.co/zpwORPSXb2
— roon (@tszzl) August 23, 2024
However, despite our long-term bullishness, several open questions facing the AI industry will determine whether we continue climbing the exponential or pause and consolidate for a while. As we enter 2025, we have five big questions:
- is pretraining hitting a wall?
- do the scaling laws hold for test time compute?
- how do we solve reasoning?
- when will the nation-state race begin?
- what’s the next big breakthrough?
We will highlight each of these below and briefly share our own color. But it’s important to note that no one — not OpenAI and certainly not us — can definitively answer any of these questions. Only the god machine can see that far ahead.

Ever since Google’s Attention Is All You Need paper in 2017, the Transformer architecture has slowly eaten the AI space. It’s now the most popular paradigm across modalities like text, code, and audio.
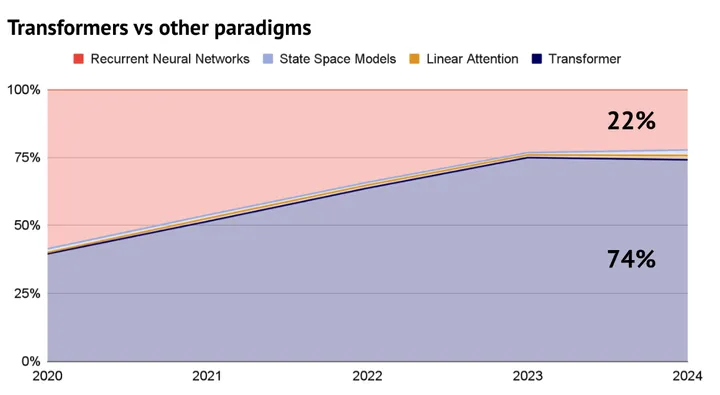
Even Tesla recently revealed that they switched to transformers to help with FSD’s lane segmentation.
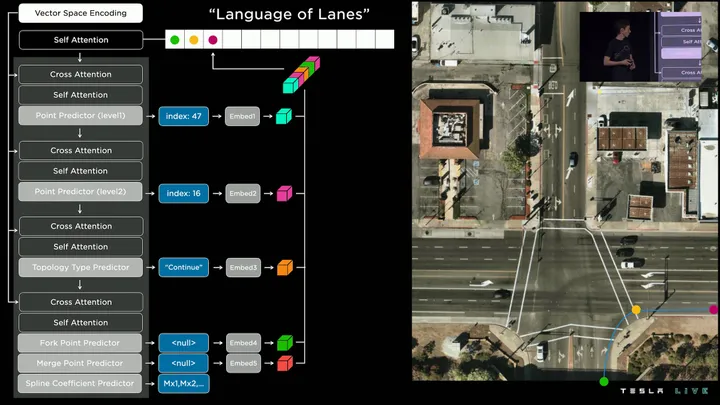
The popularity of transformers boils down to their self-attention mechanism, which lets them process inputs in parallel rather than sequentially. This makes them far more scalable than other architectures. You can literally just throw compute at them, and they get better. It’s perhaps the closest we’ve ever come to alchemy.
Sora performance scales with compute pic.twitter.com/ceuQYcSXT2
— Tsarathustra (@tsarnick) February 16, 2024
After seeing how well transformers scale, researchers at OpenAI popularized the concept of the “scaling laws.”
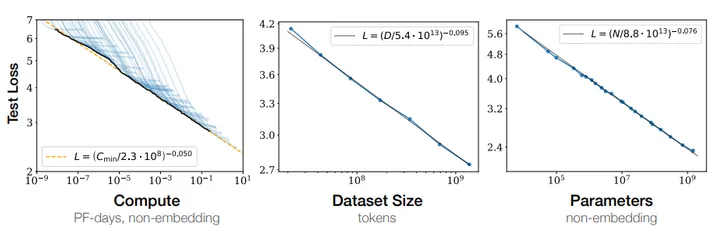
Scaling Laws for Neural Language Models
These ‘laws’ provocatively make the case that bigger models = better models. The obvious implication is that we can just scale our way to AGI.
do you own the means of production anon? the digital oceans where leviathans swim
— roon (@tszzl) February 17, 2024
For a few years, the scaling laws were considered Gospel. GPT-2 through GPT-4 were held up as proof of this relationship between scale and capabilities.
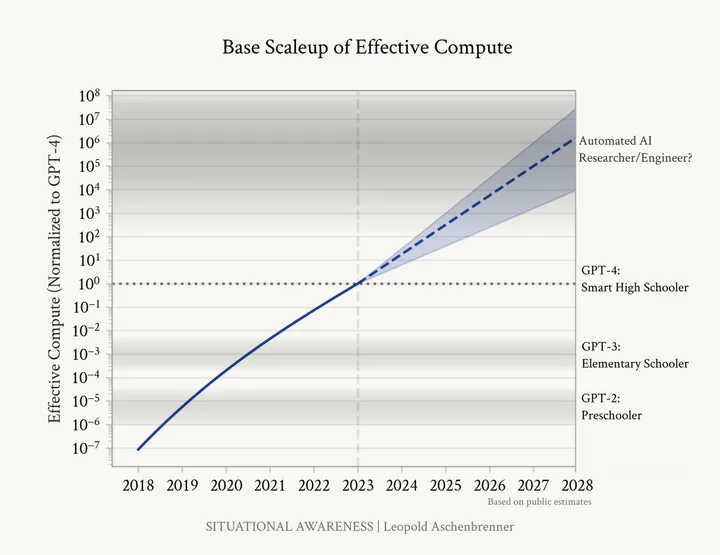
The fact that we can just make models bigger and almost magically get better performance has led to a race for scale. It has driven labs like OpenAI and Anthropic to build bigger and bigger clusters in order to train larger and larger models.
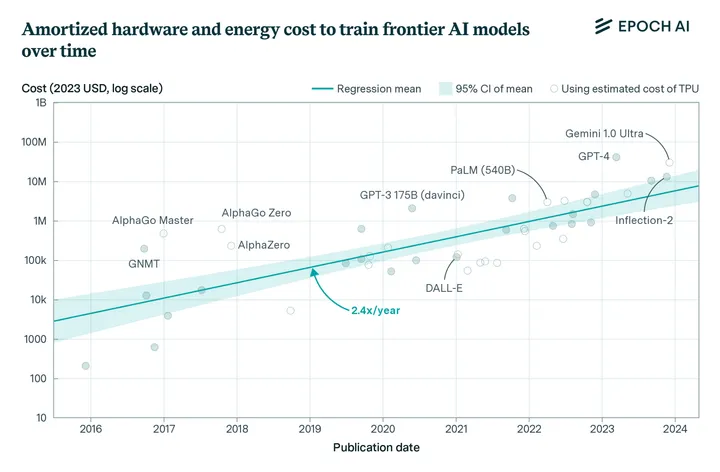
But cracks have begun to emerge in the scaling laws, or perhaps more accurately, constraints. The pretraining process — where models lazily train off the entire Internet — requires a massive amount of inputs, most notably, electricity. This poses a problem for the grid, which has grown accustomed to ~5% growth over the past decade. Our infrastructure is simply not ready for electricity demand to double over the coming decade.
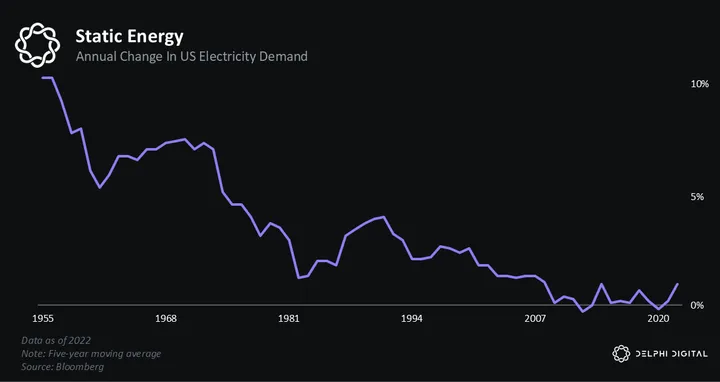
The hyperscalers are attacking this problem in different ways. Labs like Amazon, Google, and Microsoft — which signed climate pledges years ago that hold them to specific emissions targets — are racing to lock down nuclear power. But the US nuclear industry has been in perpetual decline since the Cold War. And most of these plants will take years, if not decades, to come back online.

Labs like xAI, which are not bound by the same environmental commitments, have resorted to burning natural gas in order to quench the thirst of their GPUs.

The high-stakes game of locking down power highlights the challenge that lies ahead. If scale is really all you need, then we will need a lot more power soon. But where will it come from? Renewables are suboptimal because data centers require a steady stream of electricity that doesn’t vary based on the wind blowing or sun shining. And nuclear, while promising, is in no state to scale up 10x any time soon. The obvious answer, at least for the US, seems to be natural gas. But it’s an open question whether the labs have the political stomach to start boiling the oceans in pursuit of silicon supremacy.
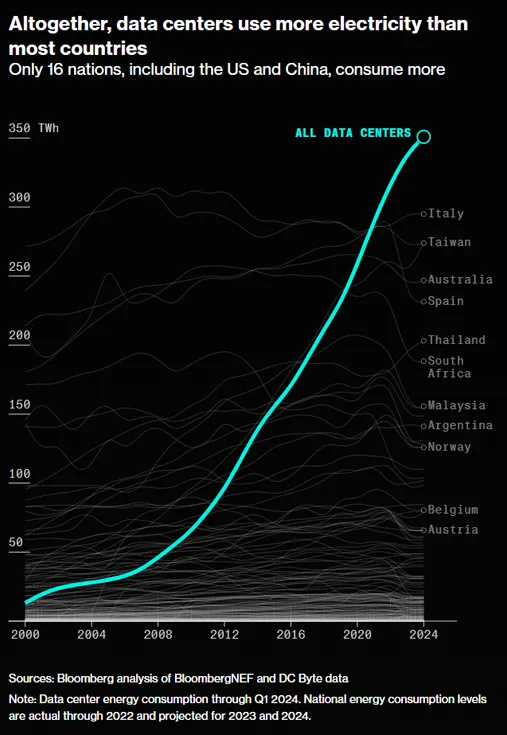
Aside from the question of “where will the power come from,” AI labs are also contending with other constraints imposed by the pretraining process. Data is the biggest. During pretraining, models consume vast amounts of data. They learn connections between words and model complex relationships by consuming trillions of tokens. This process requires a lot of data. In the early days, models would simply read the Internet. But we’ve reached the point where even this massive corpus of text is insufficient to yield further performance gains.

Text Is the Universal Interface
Yet again, the leading labs are trying to solve this problem in similar, albeit distinct ways. OpenAI has been the most proactive about partnering with legacy media outlets to gain access to their data. This approach seems to be, at best, a temporary solution as companies like News Corp, TIME, and others only have so much data to share.

Google appears to have a clear advantage on the data front since it can tap YouTube, Gmail, and all its other honeypots. But it’s been rumored that OpenAI and others already trained off these sources, despite it being against the terms of service, so it’s unclear how much of an advantage this actually is. Other players like xAI can also access real-time data via platforms like Twitter. But again, most of this data isn’t the high-quality kind they need to keep pushing the frontier.

Another strategy that’s being pursued is synthetic data. This approach typically involves a larger model generating data that’s used to train a smaller model. We’ve seen some indications this method is kinda working. Anthropic appears to have used Opus, their largest model, to generate training data for Claude Sonnet, their mid-sized model. And OpenAI is reportedly using o1 to create synthetic data for GPT-5/Orion.
Claude 3 was trained on synthetic data (“data we generate internally”).
Fairly clear that compute is the bottleneck given that parameter count and data can be scaled. https://t.co/SKxe6qOQrD pic.twitter.com/0H9EqZOoXp
— Justin Halford (@Justin_Halford_) March 4, 2024
However, just the other day, Ilya Sutskever — one of the fathers of the scaling laws — poured cold water on current techniques by saying, “Pretraining as we know it will end,” and synthetic data, in its current state, is still an unsolved problem. So, it remains to be seen how these labs will overcome the impending walls the pretraining paradigm presents.
Ilya has so much fucking Aura
There is no one in AI that comes close. The GOAT says something like “data is the fossil fuel of AI” and everyone instantly agrees. pic.twitter.com/O4ddKiC5OK
— Lisan al Gaib (@scaling01) December 13, 2024
Our view is these issues are constraints, not unsolvable problems. Scaling energy production requires human coordination, capital, and political will. While scaling data can probably only be solved through new techniques like synthetic data or more efficient algorithms. However, we tend to agree with Ilya. Pretraining does, indeed, appear to be plateauing, and the field can no longer solely rely on the “bigger is better” formula that got us this far.
One of the best points that someone made to me once was this:
“Humans generalize on far less data than AI currently does. That means there’s something our brains are doing algorithmically to do far more with far less data. Until we figure out that paradigm, we are no where near… https://t.co/IoaRRQv28y
— David Shapiro ⏩ (@DaveShapi) December 13, 2024
Our next key question heading into 2025 centers around test time compute. Historically, every time you asked chatGPT a question, it took the same amount of time and resources to answer. This never made much sense because, obviously, some questions are harder than others. If you were to ask a human, “What’s 1 + 1” and then ask, “What’s the meaning of life,” the latter question would require far more time and brain cycles to answer. But right now, models devote the same amount of resources to both.
However, OpenAI’s o1 model uses a technique called test time compute, which lets models ‘ponder.’ This is a critical breakthrough that gives AI time to ‘think’ about harder questions like “What’s the meaning of life?” before answering. Aside from achieving SOTA-level reasoning on key benchmarks, this approach also appears to have unlocked a new scaling paradigm.
o1 is trained with RL to “think” before responding via a private chain of thought. The longer it thinks, the better it does on reasoning tasks. This opens up a new dimension for scaling. We’re no longer bottlenecked by pretraining. We can now scale inference compute too. pic.twitter.com/niqRO9hhg1
— Noam Brown (@polynoamial) September 12, 2024
Instead of solely relying on larger clusters, o1 suggests we can eke out further performance gains by letting models think for longer. This approach is more economical and could help labs sidestep some of the scaling constraints we mentioned above. While it’s still early days, o1 and its broader implications have generated enormous excitement within the field. It’s probably the single biggest breakthrough of 2024.
Anyone who still believes that the development of AI has reached its limits should watch this video excerpt from Noam Brown (OpenAI).
Sometimes I get the feeling people arent listening closely.
Noam Brown: “We saw that like yeah it, once it’s able to think for longer it um… pic.twitter.com/cwqFyX8Eto
— Chubby♨️ (@kimmonismus) November 12, 2024
We believe test time compute will be a key area to watch next year. OpenAI has a clear lead, but we expect Anthropic and other labs to release their own flavor of reasoning models within the next few months. If the scaling laws hold for inference, like they do for training, we believe the performance gains we have seen in recent years will continue.
I have now run enough o1 experiments with fellow academics on their hard problems in fields ranging from neurology to genetics to economics that I believe that it has genuine potential to help with science & academics should try it to see.
Even when it is off, it spurs thinking.
— Ethan Mollick (@emollick) December 12, 2024
Our third question is — how do we solve reasoning? Right now, models are essentially just super smart stochastic parrots. They can memorize the Internet, but can’t count the R’s in the word Strawberry. The fundamental problem is they do not know how to reason. So, they usually fall over if they face a problem they haven’t encountered in their training data. This leads to some amusing failures that you would think an AI that scores on par with PhDs on some metrics would easily solve.
Here’s an example of a prompt that current models struggle to get right:
If I’m holding a glass of water and vertically rotate the glass 360 degrees, where is the water?
It doesn’t take a genius to think about this scenario and realize the water would be on the ground. A child could reason about this. But the current models fail because they have no grounding and cannot reason coherently about the world.

o1 is the first model that’s shown any ability to ‘reason’ about the world. It does this through chain of thought reasoning (akin to a human’s internal monlogue) and ‘thinking step by step.’ It remains to be seen whether this is enough to solve reasoning or if additional breakthroughs are needed. But at the very least, we expect scaling test time compute, the core innovation behind o1, to yield impressive advances in reasoning ability.
one interesting thing is o1 can clearly do complicated geometry problems with no visuals. it approaches them completely symbolically, perhaps with some invisible world model in its activation states
— roon (@tszzl) September 14, 2024
Another interesting research direction we are watching is what Nous Research calls “hunger.” They are essentially trying to teach models that things in the real world cost money, and if they cannot pay for stuff like inference, they will die. While this is not reasoning in the classical sense, we believe it’s a key unsolved problem with applications across the field. Nous is essentially trying to ground its models in the real world, which we see as an critical step toward general reasoning. After all, how can you reason about where the water is if you don’t first understand your role in rotating the glass?
glad you remember/asked about this!!
once the general transaction capabilities are restored, we’ll bring in the hunger metric. this guy should be paying for his own inference soon enough
— NEVER TOO MUCH (@karan4d) December 5, 2024
The penultimate question we will be watching in 2025 is — when will the nation-state race to AGI begin? So far, we’ve yet to see the game-theoretic race that many predicted. We think it’s coming; it’s just a matter of when. The US currently dominates the field across every conceivable metric — funding, research, capabilities, etc.
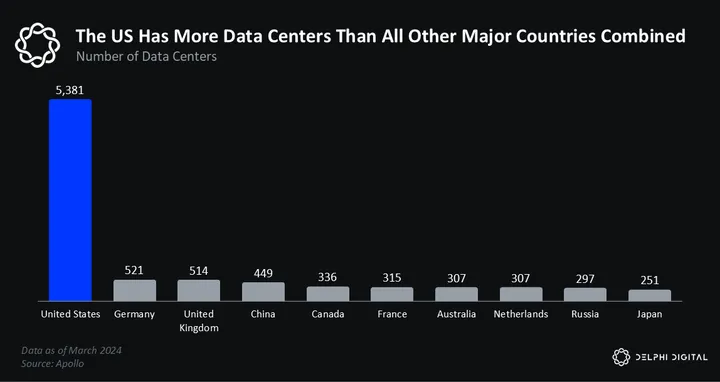
The US has also (surprisingly) been the most proactive on regulation. To be clear, there’s much more work to be done on this front. But the recent White House memorandum was the most overt indication that the US government is taking the AI race seriously. We expect other flags to come to a similar realization next year.
It is now the official policy that the United States must lead the world in the ability to train new foundation models. All government agencies will work to promote these capabilities. pic.twitter.com/LWpls1ivGy
— Andrew Curran (@AndrewCurran_) October 24, 2024
We are already seeing frontier labs draw closer to the US government. For instance, Paul Nakasone, the previous leader of the NSA, joined OpenAI’s board this year and sent shockwaves through the AI community. And the recent partnerships between major labs and defense tech start-ups hint at a behind-the-scenes effort within the US government to push for national cohesion.
Anthropic partners with Palantir
OpenAI partners with Anduril
Anduril partners with Palantir!Everybody is partnering with everybody? What does it all mean pic.twitter.com/EBcsDCbC2X
— Deedy (@deedydas) December 7, 2024
Outside the US, other countries have been slower in coming to terms with AI’s strategic importance. Europe is still trying to regulate its way to AGI…
Europeans watching Sora videos on the internet. pic.twitter.com/H52xdDy9FR
— ᐱ ᑎ ᑐ ᒋ ᕮ ᒍ (@Andr3jH) December 15, 2024
And China has not yet adopted the same state-driven investment push we see in other strategic fields like manufacturing and semiconductors. This reticence is, admittedly, somewhat puzzling, but we expect China to eventually become AI-pilled and start building data centers like they built hospitals during COVID. We also predict that at least one major European country (our money is on France) will break ranks next year and implement AI-friendly policies to compete with the US and other world powers.
Vladimir Putin says that AI systems have learned the skills of thinking and reasoning, which will lead to artificial general intelligence, surpassing humans at intellectual activities and the acceleration of science pic.twitter.com/Jl94aVKXyU
— Tsarathustra (@tsarnick) December 14, 2024
Our final question heading into 2025 is — what will be the next breakthrough? This year brought us significant algorithmic advances like o1, but we’ve also seen saturated benchmarks, with new models showing little sign of improvement. So, as the calendar flips, the field is split. People like Sam Altman think rapid progress towards AGI will continue, while others like Sundar Pinchai say that all the low-hanging fruit has already been picked.
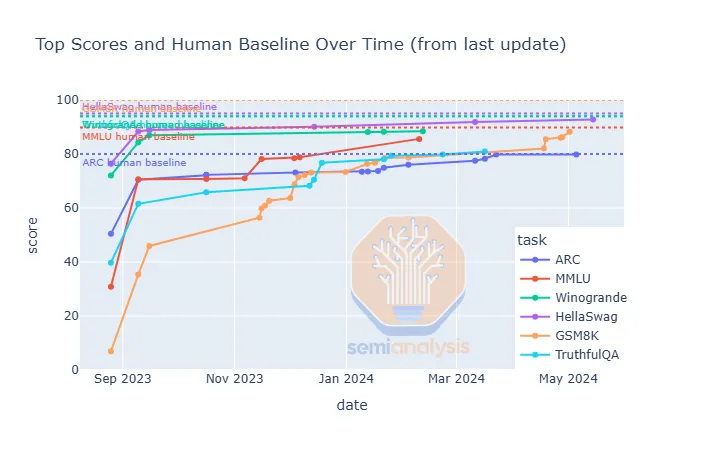
We believe we are already in a period of slight stagnation. And the media / X dot com poasters are just catching on to it now. But we also see reason for optimism. The biggest factor is o1. It proves that pretraining is no longer the only way to scale models. And its release has unlocked a new unexplored dimension for scaling. This could lead to a future where techniques are ‘stacked’ on top of each other, and together, they accomplish similar performance gains to the raw scaling of data centers.
Ex-OpenAI chief research officer Bob McGrew says that o1 is really GPT-5 because it represents a 100x compute increase over GPT-4 and the release of GPT-4.5 will be an interesting reveal of how pre-training progress stacks with the reinforcement learning process pic.twitter.com/XThIxwmTxW
— Tsarathustra (@tsarnick) December 18, 2024
The open source community could also spark the next breakthrough. But this comes with a major asterisk. To date, the leading edge of AI has been dominated by closed models from OpenAI, Anthropic, and Google. However, open source has somewhat closed the gap, primarily thanks to Zuck’s contrarian bet on opening sourcing Meta’s Llama models.

As a result, the open source community finds itself highly reliant on the benevolence of our new Drip Overlord. So far, the bet seems to be paying off handsomely for Meta. They bought themselves a bunch of goodwill and have also received a ton of free R&D from the open source community. But as the models grow bigger, costs rise, and capabilities increase, we wonder what Zuck’s tolerance will be for continued open sourcing.

It’s not hyperbole to say that Zuck is the most important figure in the open source movement. If Llama’s weights stay open, we expect incredible innovation to emerge from the open source space, as we will highlight later in this report. But if Zuck were to change his mind, perhaps due to safety concerns or mounting costs, we worry that open source efforts will struggle to compete against their well-funded closed competitors.
The Information
The third research direction we will be watching in 2025 is agents. This has been a long-standing narrative in web2 and web3 AI. But so far, we’ve seen scant progress on this front. The limiting fact continues to be reasoning. Current SOTA models are pretty good at one-off tasks like: “generate this image,” “tell me who won the Knicks game last night,” and “clean this dataset.” However, they struggle to operate in unstructured environments that require multi-step reasoning.
“llms can’t reason”, he screamed into the self assembling dyson sphere pic.twitter.com/3SBsL6imX3
— bayes (@bayeslord) October 12, 2024
Every major lab is not-so-secretly working on agents, and has been for some time. So, we expect to see notable progress on this front next year. We are also curious to see how agents behave in the real world. As Ilya Sutstekver recently said, the more a model reasons, the less predictable it becomes. The leading labs will likely be quite cautious with their releases, so this presents a unique opportunity for open source, crypto-native agents to leapfrog their closed source competitors.
Ilya Sutskever, speaking at NeurIPS 2024, says reasoning will lead to “incredibly unpredictable” behavior and self-awareness will emerge in AI systems pic.twitter.com/TeXALqG859
— Tsarathustra (@tsarnick) December 13, 2024
Just as markets climb walls of worry, so too do new technologies. AI has made incredible strides in recent years, but challenges still lie ahead as the scaling laws look more tenuous than ever. But we remain optimistic. The leading labs are all sitting on unreleased models that promise to push the state of the art next year. And the new US administration looks poised to unlock unprecedented investment in chips, data centers, and other key initiatives. In short, the macro AI outlook is bright.
Before we venture deeper into this report, it’s worth pausing to reflect
Read the full report
This report is part of Delphi Pro.
- 800+ Pro reports across every major sector
- Talk directly with our analysts
- Private community of funds and builders
Already a Pro member? Log in
0 Comments